While debugging, you may need an interactive console at hand... This is easy: During debugging, switch to the Debugger Console,
and then press the lowest button in its toolbar. The console becomes interactive and it shows a prompt, where you can enter commands
and view output.
Press Ctrl+Shift+I (View | Quick Definition) to preview the definition or content of the symbol at caret, without having to open
it in a separate editor tab.
To return to the last place where you made changes in code, press Ctrl+Shift+Backspace or select Navigate | Last Edit Location
from the main menu.
If you press Ctrl+Shift+Backspace several times, you see later deeper into your changes history.
Manage incoming GitHub pull requests directly from PyCharm Community: from the main menu select VCS | Git | View Pull Requests.
PyCharm Community lets you assign and merge pull requests, view the timeline and inline comments, submit comments and reviews, and
accept changes without leaving the IDE:
When you press Alt+Enter to invoke a quick-fix or an intention action, press the right arrow key to reveal the list of additional
options. Depending on the context, you can choose to disable the inspection, fix all problems, change the inspection profile, and so
on.
Use shortcuts to comment and uncomment lines and blocks of code: Ctrl+\ for single line comments ( Chrl+Shift+/: for block
comments ( /*...*/ )
Press Ctrl+K to invoke the Commit Changes dialog.
It shows all modifications in a project, provides files' status summary, and suggests improvements before checking in.
Press Ctrl+D in the editor to duplicate the selected block, or the current line when no block is selected.
To access the essential VCS commands, select VCS | VCS Operations Popup from the main menu or press Alt+'. A popup with the VCS
commands that are relevant tc the current context will open:
PyCharm Community allows configuring Python interpreters on the various stages of development:
* When a project is only being created (File I New Project, or Create New Project on the Welcome screen).
* In an already existing project, use the Python Interpreter widget in the Status bar or select Project I Python Interpreter
in the project Settings/Preferences.
When some words are missing in the pre-defined dictionaries, you can create your own. A custom dictionary is a .die text file
containing each word on a new line.
All you have to do is add the directories where your dictionaries are stored in Settings/Preferences | Editor | Spelling.
Use the Run/Debug Configuration dialog to automatically submit input values from a text file instead of typing them in the Run
tool window.
To enable redirecting, select the Redirect input from checkbox and specify the path to the target file.
Use Alt+Shift+C to quickly review recent changes to the project.
PyCharm is cross-platform,
with Windows, macOS and Linux versions.
The Community Edition is released under the
Apache License,
and there is also Professional Edition released under a
proprietary
license - this has extra features.
Features
Coding assistance and
analysis, with
code completion,
syntax and error highlighting, linter integration, and quick fixes
Project and code navigation: specialized project views, file structure views and quick jumping
between files, classes, methods and usages
Python refactoring:
including rename, extract method, introduce variable, introduce constant, pull up, push down and
others
The Pros and Cons of Using Jupyter Notebooks as
Your Editor for Data Science Work
TL;DR: PyCharm's probably better
Steffen Sjursen
Follow
Mar 1
· 5 min read
Image by
Gerd
Altmann
from
Pixabay
Jupyter notebooks have three particularly strong benefits:
They're great for showcasing your work. You can see both the code and the results. The notebooks at
Kaggle
is
a particularly great example of this.
It's easy to use other people's work as a starting point. You can run cell by cell to better get an understanding of
what the code does.
Very easy to host server side, which is useful for security purposes. A lot of data is sensitive and should be
protected, and one of the steps toward that is no data is stored on local machines. A server-side Jupyter Notebook setup
gives you that for free.
When prototyping, the cell-based approach of Jupyter notebooks is great. But you quickly end up programming several steps --
instead of looking at object-oriented programming.
Downsides of Jupyter notebooks
When we're writing code in cells instead of functions/classes/objects, you quickly end up with duplicate code that does the
same thing, which is
very
hard to maintain.
Don't get the support from a powerful IDE.
Consequences of duplicate code:
It's hard to actually collaborate on code with Jupyter -- as we're copying snippets from each other it's very easy to get
out of sync
Hard to maintain one version of the truth. Which one of these notebooks has the one true solution to the number of
xyz?
There's also a tricky problem related to plotting. How are you sharing plots outside of the data science team? At first,
Jupyter Notebook is a great way of sharing plots -- just share the notebook! But how do you ensure the data there's fresh?
Easy, just have them run the notebook.
But in large organizations, you might run into a lot of issues as you don't want too many users having direct access to the
underlying data (for GDPR issues or otherwise). In practice, in a workplace, we've noticed plots from Jupyter typically get
shared by copy/pasting into PowerPoint. It's highly ineffective to have your data scientists do copy/paste cycles whenever
the data changes.
This was very easy to get started on. I just copied some cells from the introductory examples and then explored on my own.
But here we also see the downside -- access-credentials management is now duplicated across all of the notebooks. What if
they change? Then, every notebook needs to be changed as well.
The dataset is interesting. But there's no canonical one -- so if you want to reuse it, you're copying the SQL statement.
With poor discipline, you can also move into weird versioning issues where you start accumulating multiple Jupyter
notebooks that no one remembers.
Benefits from an IDE
As alternatives to Jupyter Notebook, you could checkout Spyder and PyCharm.
Spyder has an interesting feature where it's very good at reloading code while keeping the state of your current session.
Thus, Spyder is great if you're trying to do most of your transformations in pandas or some other tool on your local
machine. It also comes with Anaconda, if that's your Python distribution of choice.
PyCharm is really good at building proper Python code and getting replicable results. There's a lot of functionality for
greater productivity. Both Spyder and PyCharm enable cell-based processing with
#%%
comments
in your code, so we can still prototype code in the same way as in Jupyter Notebook.
For one of our previous clients, we wanted to improve code quality but were not allowed to access data on any local
machines. So we spent the effort to spin up VMs with PyCharm to get access to data in a secure manner. It paid off quickly
-- development speed and code quality increased by a factor of
a
lot.
And code made it into production a lot faster as well.
Getting machine learning into production
Something to think about is where computations are run. For code that's easy to put into Docker, deploying that to any
cloud solution is easy. For notebooks, there are also good options, though you're more locked into specific solutions.
If you do want to look into Jupyter notebooks, it's definitely worth looking into
Amazon
SageMaker
and/or
Kubeflow
.
These solutions enable easier deployment to production for code in notebooks.
We've had a lot of success with the following approach:
Use PyCharm (which has improved code quality by a far bit)
Every transformation of data needs to exist in exactly one place in our repository. (So any issues with that
transformation needs to be fixed in
that one place.
)
Every transformation needs to be in production (so available as a table/file/output), so other data scientists can reuse
it in their models. And if that transformation improves, all subsequent pipelines are automatically improved as well.
Conclusion
Should you remove notebooks completely? Notebooks have a lot of pros. It depends on where you are and what your main
concerns are
If all of the machine learning is already on the cloud and only needs some light scripting -- notebooks are probably the
easiest way there
Be careful with a heavy reliance on notebooks when the data-engineering team is short staffed or when the data scientist
team is immature -- as this is when you can build up an unmanageable amount of bad habits and technical debt in a short
amount of time
If your problems are fairly unique and require a lot of self-developed code, Jupyter notebooks will grow in size and
complexity in ways that'll be hard to maintain
The larger the team, the more concerns we have about collaborative coding and the reuse of results between team members,
and we should be moving away from Jupyter
If you have cross-functional teams, with both software engineers and data scientists, getting the most out of version
control and object-oriented programming is easier. If you have a cross-functional team, you'll probably get more
benefits by moving away from Jupyter.
The Pros and Cons of Using Jupyter Notebooks as
Your Editor for Data Science Work
TL;DR: PyCharm's probably better
Steffen Sjursen
Follow
Mar 1
· 5 min read
Image by
Gerd
Altmann
from
Pixabay
Jupyter notebooks have three particularly strong benefits:
They're great for showcasing your work. You can see both the code and the results. The notebooks at
Kaggle
is
a particularly great example of this.
It's easy to use other people's work as a starting point. You can run cell by cell to better get an understanding of
what the code does.
Very easy to host server side, which is useful for security purposes. A lot of data is sensitive and should be
protected, and one of the steps toward that is no data is stored on local machines. A server-side Jupyter Notebook setup
gives you that for free.
When prototyping, the cell-based approach of Jupyter notebooks is great. But you quickly end up programming several steps --
instead of looking at object-oriented programming.
Downsides of Jupyter notebooks
When we're writing code in cells instead of functions/classes/objects, you quickly end up with duplicate code that does the
same thing, which is
very
hard to maintain.
Don't get the support from a powerful IDE.
Consequences of duplicate code:
It's hard to actually collaborate on code with Jupyter -- as we're copying snippets from each other it's very easy to get
out of sync
Hard to maintain one version of the truth. Which one of these notebooks has the one true solution to the number of
xyz?
There's also a tricky problem related to plotting. How are you sharing plots outside of the data science team? At first,
Jupyter Notebook is a great way of sharing plots -- just share the notebook! But how do you ensure the data there's fresh?
Easy, just have them run the notebook.
But in large organizations, you might run into a lot of issues as you don't want too many users having direct access to the
underlying data (for GDPR issues or otherwise). In practice, in a workplace, we've noticed plots from Jupyter typically get
shared by copy/pasting into PowerPoint. It's highly ineffective to have your data scientists do copy/paste cycles whenever
the data changes.
This was very easy to get started on. I just copied some cells from the introductory examples and then explored on my own.
But here we also see the downside -- access-credentials management is now duplicated across all of the notebooks. What if
they change? Then, every notebook needs to be changed as well.
The dataset is interesting. But there's no canonical one -- so if you want to reuse it, you're copying the SQL statement.
With poor discipline, you can also move into weird versioning issues where you start accumulating multiple Jupyter
notebooks that no one remembers.
Benefits from an IDE
As alternatives to Jupyter Notebook, you could checkout Spyder and PyCharm.
Spyder has an interesting feature where it's very good at reloading code while keeping the state of your current session.
Thus, Spyder is great if you're trying to do most of your transformations in pandas or some other tool on your local
machine. It also comes with Anaconda, if that's your Python distribution of choice.
PyCharm is really good at building proper Python code and getting replicable results. There's a lot of functionality for
greater productivity. Both Spyder and PyCharm enable cell-based processing with
#%%
comments
in your code, so we can still prototype code in the same way as in Jupyter Notebook.
For one of our previous clients, we wanted to improve code quality but were not allowed to access data on any local
machines. So we spent the effort to spin up VMs with PyCharm to get access to data in a secure manner. It paid off quickly
-- development speed and code quality increased by a factor of
a
lot.
And code made it into production a lot faster as well.
Getting machine learning into production
Something to think about is where computations are run. For code that's easy to put into Docker, deploying that to any
cloud solution is easy. For notebooks, there are also good options, though you're more locked into specific solutions.
If you do want to look into Jupyter notebooks, it's definitely worth looking into
Amazon
SageMaker
and/or
Kubeflow
.
These solutions enable easier deployment to production for code in notebooks.
We've had a lot of success with the following approach:
Use PyCharm (which has improved code quality by a far bit)
Every transformation of data needs to exist in exactly one place in our repository. (So any issues with that
transformation needs to be fixed in
that one place.
)
Every transformation needs to be in production (so available as a table/file/output), so other data scientists can reuse
it in their models. And if that transformation improves, all subsequent pipelines are automatically improved as well.
Conclusion
Should you remove notebooks completely? Notebooks have a lot of pros. It depends on where you are and what your main
concerns are
If all of the machine learning is already on the cloud and only needs some light scripting -- notebooks are probably the
easiest way there
Be careful with a heavy reliance on notebooks when the data-engineering team is short staffed or when the data scientist
team is immature -- as this is when you can build up an unmanageable amount of bad habits and technical debt in a short
amount of time
If your problems are fairly unique and require a lot of self-developed code, Jupyter notebooks will grow in size and
complexity in ways that'll be hard to maintain
The larger the team, the more concerns we have about collaborative coding and the reuse of results between team members,
and we should be moving away from Jupyter
If you have cross-functional teams, with both software engineers and data scientists, getting the most out of version
control and object-oriented programming is easier. If you have a cross-functional team, you'll probably get more
benefits by moving away from Jupyter.
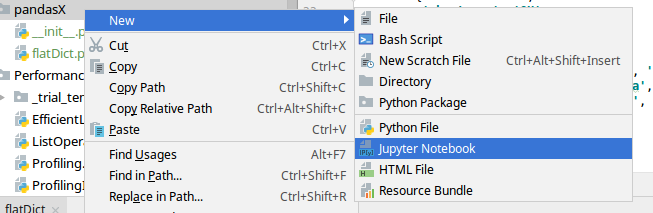
PyCharm support working with Jupyter Notebooks local and remote connection. You can create new Jupyter Notebook by right
click of the mouse and selecting:
New
Jupyter Notebook
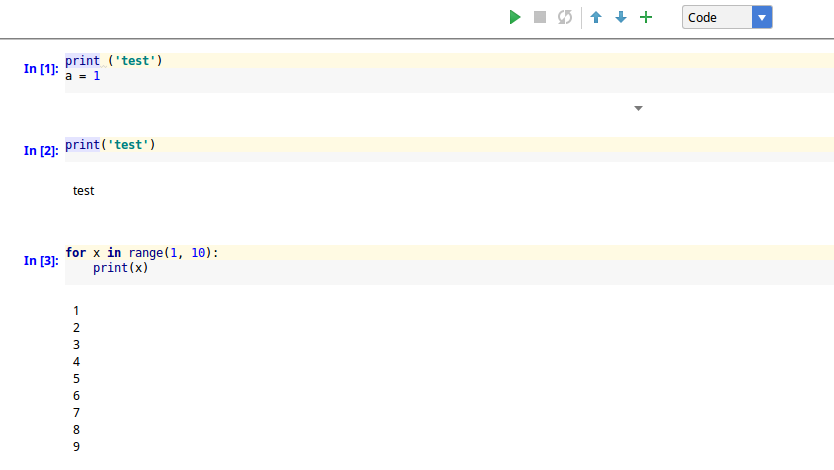
Then you can add new cells and enter code or Markdown.
Once the cell is created and fill with code you can executed:
Mark Lutz's
Learning Python is a favorite of many. It is a good book for novice programmers. The new fifth edition is updated to both Python 2.7 and 3.3. Thank you for your feedback!
Your response is private. Is this answer still relevant and up to date?
Instead of book, I would advice you to start learning Python from
CodesDope which is a wonderful site for starting to learn
Python from the absolute beginning. The way its content explains everything step-by-step and
in such an amazing typography that makes learning just fun and much more easy. It also
provides you with a number of practice questions for each topic so that you can make your topic
even stronger by solving its questions just after reading it and you won't have to go around
searching for its questions for practice. Moreover, it has a discussion forum which is really
very responsive in solving all your doubts instantly.
There are many good websites for learning the basics, but for going a bit deeper, I'd
suggest
MIT OCW 6.00SC. This is how I learned Python back in 2012 and what ultimately led me to MIT
and to major in CS. 6.00 teaches Python syntax but also teaches some basic computer science
concepts. There are lectures from John Guttag, which are generally well done and easy to
follow. It also provides access to some of the assignments from that semester, which I found
extremely useful in actually learning Python.
After completing that, you'd probably have a better idea of what direction you wanted to go.
Some examples could be completing further OCW courses or completing projects in Python.
(stackoverflow.blog)
253 Posted by EditorDavid on Saturday September 09, 2017 @09:10PM from the is-simple-better-than-complex?
dept. An anonymous reader quotes Stack Overflow Blog: In this post, we'll explore the extraordinary
growth of the Python programming language in the last five years, as seen by Stack Overflow traffic
within high-income countries.
The term "fastest-growing" can be hard to define precisely, but we
make the case that Python
has a solid
claim to being the fastest-growing major programming language ... June 2017 was the first month
that Python was the most visited [programming language] tag on Stack Overflow within high-income
nations. This included being the most visited tag within the US and the UK, and in the top 2 in almost
all other high income nations (next to either Java or JavaScript). This is especially impressive
because in 2012, it was less visited than any of the other 5 languages, and
has grown by 2.5-fold in that time .
Part of this is because of the seasonal nature of traffic
to Java. Since it's heavily taught in undergraduate courses, Java traffic tends to rise during the
fall and spring and drop during the summer. Does Python show a similar growth in the rest of the
world, in countries like India, Brazil, Russia and China? Indeed it does.
Outside of high-income
countries Python is still the fastest growing major programming language; it simply started at a
lower level and the growth began two years later (in 2014 rather than 2012). In fact, the year-over-year
growth rate of Python in non-high-income countries
is slightly higher than it is in high-income countries ...
We're not looking to contribute to
any "language war." The number of users of a language doesn't imply anything about its quality, and
certainly can't tell you which language is more appropriate for a particular situation.
With that
perspective in mind, however, we believe it's worth understanding what languages make up the developer
ecosystem, and how that ecosystem might be changing. This post demonstrated that Python has shown
a surprising growth in the last five years, especially within high-income countries.
The post
was written by Stack Overflow data scientist David Robinson, who notes that "I used to program primarily
in Python, though I have since switched entirely to R."
Steffen Sjursen Follow Mar 1 · 5 min read



Published 2 years ago 2 min read By John D K