|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
| News | See also | Recommended Links | Books | Articles | Sample Programs |
| REXX | C | Perl | Structured programming as a religious cult | Program proofs pseudoscience | A Slightly Skeptical View on the Object-Oriented Programming |
| PL/C | PL/M | Multics | History | Humor | Etc |
|
|
PL/1 is an important language with two extremely high quality compliers created by IBM. Unfortunately it suffered tragic, undeserved destiny and is almost forgotten today. It should have been the Cobol replacement, but never managed to perform this role with the exception of USSR and Eastern block countries. Like any innovative technology it suffered severe blows from IBM mis-marketing (IBM did a tremendous job in development of the language and compilers, but excessive greed doomed those efforts). IBM should have made debugging compiler free and charge money only for optimizing complier. Another helpful move would be releasing of old F-complier as a public domain product.
Until PL/1 was developed, all previous languages had focused on one particular area of application, such as numerical computations, artificial intelligence, or business. PL/1 was the first designed as universal language and that was a tremendous breakthrough. It was the first successful attempt to design a language that could be used in a variety of application areas. Again, in many areas it was far advanced for its time (it is a higher level language then C that was created a decade later based on its creator experience with usage of PL/1 in Multics) and that hurt the adoption. Another factor that contributed to PL/1 demise was absence of free high quality compilers. We well as complexity of compilers as such. Commercial compilers were pretty expensive. In Eastern Europe they were supplied as part of the standard OS distribution for mainframes. That contributed to tremendous success of PL/1 in this region and suggests that if IBM provided PL/1 compilers for free the language might be tremendously more successful that it was in the USA.
The language also suffered from misguided or plain vanilla stupid "gurus" of programming language community such as the "father of structured programming" Edgar Dijkstra -- one of the first religious fanatics in the area of programming languages. . It became a favorite target of misguided criticism from "purists" in language design. Niklaus Wirth (who was really talanted language designer but who never created product equal inscope and depth to PL/1; he was kind of one-man show in complier design. ) and Edgar Dijkstra (with his dogma of structured programming first and verification crazy second; the latter doomed a cople of talented compliers writers such as David Grees and probably hampered the achievements of Nicklaus Wirth) were particularly influential and particularly misguided
I would like to stress that Edgar Dijkstra despite his early achievements was especially damaging with his misguided religious fervor toward program proofs and as a creator the first CS cult which perverted computer science for a decade or more...
|
|
The main reason of failure of PL/1 was that fact that in key concepts and (which is related) hardware requirements it was probably 20 years ahead of its time. Full language compilers were way too complex which depressed portability. Subsets were not that attractive. Especially toxic for complier writers were "no reserved keywords" feature and excessive syntax flexibility of Declare statement. Still it is important to understand that this was a very innovative language with very innovative, revolutionary compilers. Despite their age, in comparison with IBM debugging and optimizing compilers many modern compliers looks like outdated and badly designed junk.
Any innovative language that is in may respects too far ahead of its time needs luck to survive. For PL/1 such a luck never materialised.
Still it was the first language that contained decent string handling capabilities, pointers, three types of allocation of storage -- static, automatic (stack-based) and controlled (heap-based), exception handling, and rudimentary multitasking. While the idea of preprocessor (a front end macro generator) was never cleanly implemented (as PL/1 did not stored "macro source" line numbers and without them matching preprocessor and "real statements" was difficult) it was also innovative and later was inherited and expanded by C.
All-in-all PL/1 was and probably still is one of the most innovative programming languages in existence and some of its feature are still not matched by "new kids" in the programming language block.
It is not the only excellent product from IBM that almost disappeared. In this sense its popularity decline is not that dissimilar to decline of two other innovative and interesting IBM products: VM/CMS and OS/2.
Such feature as exception handling was so well integrated into the language that they was really used in day-to-day basis by most programmers. It was not some "exotica". It was 100% practical and robust feature of the language. In this sense PL/1 was the language that legitimized exceptions as a feature of programming languages (strangely enough it did not contained explicit coroutines as a programming language construct but "programmer defined" exception were somewhat similar)
| Such feature as exception handling was so well integrated into the language that they was really used in day-to-day basis by most programmers. It was not some "exotica". It was 100% practical and robust feature of the language. In this sense PL/1 was the language that legitimized exceptions as a feature of programming languages (strangely enough it did not contained explicit coroutines as a programming language construct but "programmer defined" exception were somewhat similar) |
PL/1 also has good string handling capabilities and three most common string handling function (substr, index, length and tr) in their modern form can be traced to this language. One problem in PL/1 implementations (but not with the language itself) was connected with the implementation decision used in IBM compilers to prefix string with its length. This was a kind of premature optimization and it created several classes of strings:
In retrospect C language designer decision to rely on the end marker was a better one, although, of course, if slows dolw langua function considerably, which was instant in PL/1. Later in languages based on garbage collection the idea of separately stored descriptors for string (kind of like the "inode" concept for file in Unix) became standard implementation method, but at the time of PL/1 such a design this was an unaffordable luxury (first mainframes used to have 64KB (not megabytes by kilobytes) of storage and PL/1 worked and worked well in such an environment. The achievement which is difficult to understand even now.
PL/1 features live in many other languages and first on all in C, which semantically can be considered as a direct derivative (limited subset) of PL/1. what is funny is that PL/1 managed to avoid several blunders that were made by designer of C.
I would like to stress that PL/1 (as a system programming language for Multics) has large influence on C -- one of the most widely used compiled programming languages and many of it's ideas directly or indirectly found its way into other programming languages. I have no information about Larry Wall possible exposure to PL/1 ( but it is a possibility) but some ideas of PL/1 can be found in Perl. IMHO he demonstrated some understanding if not PL/1 structure and semantic, but PL/1 philosophy: at some point simplicity becomes self-defeating and paradoxically complex non-orthogonal languages become simpler to use that "extensions" of a simpler language. Despite complexity they are better integrated and errors are better diagnosed as compiler recognized those structures and features as language elements and is able to perform some static checks.
| Larry Wall demonstrated some understanding if not PL/1 structure and semantic, but PL/1 philosophy: at some point simplicity becomes self-defeating and paradoxically complex non-orthogonal languages become simpler to use that "extensions" of a simpler language. |
Now both books and compilers on PL/1 became rarity, although IBM optimizing and debugging compilers on mainframes and AIX are still available and remain an unsurpassed masterpieces of software engineering.
Now let's talk a little bit in some hidden analogy between PL/1 and Perl. PL/1 was first widespread non-orthogonal language (with many ways to accomplish the same thing) and in this sense it can be viewed as a precursor to Perl and closely related to Perl philosophy.
Perl can be viewed historically as a counter reaction of Unix pushing simplicity way too far and defeating it "on the way" ("the road to hell is paved with good intention and with time number of option in classic and really simple Unix utilities became such a mess that nobody remodelers them.) The key question in this respect that should be asked is: What is so simple in a two hundred or so "simple" Unix utilities ?
Just the total number of them and differences (often subtle) in approaches in naming and handling parameters (without iron fist of corporate standard like in IBM mainframe specification or Microsoft GUI interfaces) made them a completely incomprehensible mess. There is no and can't be a person in the world that knows them all. This is too much for a human brain. In this sense complexity moved from libraries and utilities directly into the programming language can benefit programming community: this way you can if not avoid but at least somewhat tame impenetrable maze of libraries/classes, etc.
Also PL/1 is free from any religious doctrines and this make it a welcome member of programming languages family unlike all those strongly type languages or "promise much deliver little" OO languages like Java. Blunder made is design of Java are just too evident although truth be told Java was initially designed as a small language to imbedded application as as such were not designed as "universal" programming language it became later (and Cobol replacement for commercial programming) which introduced OO to the masses and completely hosed them with it. True believers in OO should probably stop reading this page at this point :-).
While PL/1 did not have coroutine mechanism it did introduced an important innovation: multi-entry subroutines (see discussion at Multiple entries in procedures below). Which allows imitation of coroutines in simple cases and also can serve as structuring mechanism similar to classes on OO programming, but will more clarity and less overhead.
Historically PL/1 was a very elegant and innovative blend of Fortran, Cobol and Algol-60 in one language. It also introduced several major innovations in programming languages design:
Both of those features were far ahead of time and complicated the complier. That was especially true of exceptions which are essentially a frozen coroutines which can be activated in the context that is different from the context of the procedure in which they are contained. As such need allocation of memory on heap.
I would mentions the following significant language features:
EVENT and TASK, the TASK-option on the CALL-statement (Fork),
the WAIT-statement (JOIN),
the DELAY(delay-time), EVENT-options on the record I/O statements and the UNLOCK statement
to unlock locked records on EXCLUSIVE files. Event data identify a particular event and indicate whether it is complete
('1'B) or incomplete ('0'B): task data items identify a particular task (or
process) and indicate its priority relative to other
tasks.PL/1 was the first mainstream language that introduced exceptions. BTW half of extensions of C++ including exceptions was related to features that creators of C removed from PL/1 when they created the language :-).
It is interesting to note that PL/1 was the first programming language that provides correct handing of such a common problem as detection of the end of the sequential file while reading. In PL/1 endfile condition is raised which activates stopped coroutine (exception handler) within which programmer can do whatever he wish but typically jump to the statement after the loop. This usage of goto is definitely superior to misguided attempts to make this test in the header of the loop like was done in C and Perl.
ON ENDFILE (SYSIN) GOTO EOF_SYSIN;
OPEN FILE (SYSIN) RECORD SEQUENTIAL;
READ FILE (SYSIN) INTO (RECORD);
DO WHILE (TRUE);
.
.
.
READ FILE (SYSIN) INTO (RECORD);
END;
EOF_SYSIN:
... ... ...
It is important to note that PL/1 was used as a system programming language for such an important operating system as Multics -- the originator of many ideas that later were re-implemented in Unix. In partially bastardized way, key ideas and most of PL/1 statements and variables semantics can be found in C which should probably be considered to be an indirect derivative and a great simplification of PL/1 core.
PL/1 actually pioneered the idea that later became quite fashionable -- the idea of classes (Simula 67 introduced essentially the same idea in a different, more general context with allocation of variables on the heap, but only in 1967). In PL/1 speak class is a multi-entry procedure. One of entry points, typically the name of the whole procedure can serve as the constructor. Others entries defined in this procedure serve as method, as they have access to the procedure namespace. Of course to have multiple instances all variables need to be allocated on the heap. But often it does not needed. They key here is not so much multiple instances, bt partitioning of variables namespace.
PL/1 leave detail on implementation up to programmer. Internal procedures can be nested that provides "poor man sub classing." If all variables were static then constructor was not really necessary and we have a class with exactly one instance.
If they are allocated on the heap they are constuctor and destructor are essential (PL/1 does not have automatic garbage collation). Of course nothing was still formalized, but that was happening in early 60th not in late 80th as with C++ ;-). and that was really revolutionary approach as computer that were really pigmies in capabilities in comparison with computer in late 80 to say nothing about today. Allocation of variable in the stack was really innovative approach in early 60th as servers at this time were really minuscule even in comparison with modern laptops; the latter are now surpassing several orders of magnitude the amount of memory event the largest of system 360 servers used to have, to say nothing about the CPU speed, the size of the harddrives. Even smartphones look like supercomputers in comparison with mainframes of late 1960th.
And there is a distinct beauty of simplicity in this implementation: this was a very simple and very effective technique of creating your own namespace for the set of procedures; It is very easy to understand and use. That's why it became the technique that any programmer can easily learn and successfully apply. So successfully that usually qualified PL/1 programmer did not write procedures in other way: multiple entry procedure became a hallmark of professional PL/1 programmers in xUSSR space.
PL/1 was one of the first languages in which the attempt to catch undefined variable at execution time were successfully implemented (the other was Hoare Algol I think). It also can if indexed used are within the subscript ranges for array.
For substipts out of range there was a special exception on subscriptrange, which you can catch and take corrective actions, if necessary. Subscript range error
The implementation was based on filling initially allocated memory space with special rare bitmask and checking in retrieval of variable if this bit mask is present. If yes, it was assumed that the variable was not initialized. PL/1 implemented did not have the luxury of having symbol tables available during the execution of the program.
PL/1 used the scheme that later became fashionable when it was reimplementation in C and later went in C++: the idea of integrated preprocessor of the language. In PL/1 as far as I know it was not widely used, but was available in all full language implementations, starting with IBM F compiler.
While severa scarcity of RAM prevented adopting the scheme is which PL/1 preprocessor stored "macro source" line numbers, it can be instantly made more useful with storce line numbers. Which can be stored in compited program and referred to in diagnostic messages if only in debug mode.
The power of PL/1 came from a well organized set of statements and types of variables that it supported. It first introduced into language all three major classes of variables that are used in modern languages: static (like in Fortran common), automatic (allocated via stack, destroyed on exit from the procedure, and controlled (heap allocation). Static variables can be local or external -- shared with other separately compiled modules.
It also contained some esoteric memory allocation features like areas of memory in which you can allocate your variables. Visibility was controlled by procedure scoping and there was special class "external variable" -- a static variable that did obey the rules on local visibility -- it was exported in linked procedures (each variable was like separate common block in Fortran).
The language contains surprisingly robust string handling capabilities including such functions that later became classic: translate (the result of idiosyncrasy of IBM/360 instruction set ;-) which later became tr in Unix), index and substr (later popularized and extended by REXX and Perl).
Some useful additional resources:
Although all those document share a typical IBM style ( in which useful information is carefully hidden or obscured ;-) there are some useful IBM documents about PL/1 too:
PL/I programs are made up of blocks. A block can be either a subroutine, or just a group of statements. A PL/I block allows you to produce highly modular applications, because blocks can contain declarations that define variable names and storage classes. Thus, you can restrict the scope of a variable to a single block or a group of blocks, or you can make it known throughout the compilation unit or a load module
PL/1 was developed as an IBM product in the mid 1960's, and was originally named NPL (New Programming Language). The name was changed to PL/1 to avoid confusion of acronym NPL with the National Physical Laboratory in England. Here is relevant quote form Wikipedia:
IBM took NPL as a starting point and completed the design to a level that the first compiler could be written: the NPL definition was incomplete in scope and in detail[10]. Control of the PL/I language[11] was vested initially in the New York Programming Center and later at the IBM UK Laboratory at Hursley. The SHARE and GUIDE user groups were involved in extending the language and had a role in IBM’s process for controlling the language through their PL/I Projects...
The language was first specified in detail in the manual “PL/I Language Specifications. C28-6571” written in New York from 1965 and superseded by “PL/I Language Specifications. GY33-6003” written in Hursley from 1967. IBM continued to develop PL/I in the late sixties and early seventies, publishing it in the GY33-6003 manual. These manuals were used by the Multics group and other early implementers.
The first compiler was delivered in 1966. The Standard for PL/I was approved in 1976.
The first PL/1 compiler that was shipped with OS/360 was so called F-compiler. In was a slow multipass compiler that was designed to operate with as little as 64K of RAM. And it is hard to believe, but first mainframes despite being very expensive computers were often shipped with just 64 or 128K of memory. This was ferrite based magnetic memory with each bit represented by a tiny physical ferrite ring crossed by wires that magnetize of demagnetize it and read the status. Only later 256K and larger amounts of memory became common.
The fits significant blow to PL/1 was from made in early 70th by religious fanatics connected to the "structured programming" dogma and, especially, Edsger W. Dijkstra inspired "verification frenzy". Now it is difficult to comprehend how almost the whole computer science was hijacked by this primitive religious doctrine. But it was true and has demonstrated quite well that the virtues ascribed to academic scientists are way overblown. A lot of academic scientists are despicable sycophants who would support any nonsense just to survive and prosper, and some and very dangerous subset are religious fanatics (Edsger W. Dijkstra represented well this personality type) or, worse, psychopathic power grabbers, who tend to create tightly controlled personal empires (Trofim Lysenko is a prominent example of this type) . As famous German physicist Max Planck sadly joked "Science advances one funeral at a time."
Heretics who are ready to be burned on the stake defending the truth are as rare in academic community as among commoners. May be even more rare. Complete corruption of academic economics, conversion of the majority of them into intellectual defenders of interests of financial oligarchy that we observed since 1980 say this pretty laud and clear. And computer scientists are not that different those days. They also depends on grants and want tenure at all costs. Which requires certain compromises.
Edsger W. Dijkstra inspired "verification frenzy" was mostly related to bogus mathematic masturbation called "correctness proofs". The idea was "simple, attractive and wrong" and due to this it soon became more fashionable that drunks fights in pubs in England. It attracted huge amount of verification snake oil salesmen and "computer science crooks" who often flooded computer science departments and eliminated useful research.
While there was a positive component in structured programming movement (it did helped to introduce richer set of programming control structured in the language and PL/1 was again pioneer in this area), but most effects were negative: such as creation of some unrealistic expectations (that number of errors in a program without goto statements is less then for the program with many goto statements; but in reality if not presence of absence of goto statements, but the usage of structured control statements that matter and if some are not available in the language they should be emulated using goto statements) or simply harmful (it is perfectly possible to write incompressible, buggy programs using just structured control statements; the lack of talent can 't be compensated by any language structures)
Edsger W. Dijkstra played the role of a fervent Ayatollah. This controversial character has the religious zeal of Luther, but was more misguided. At the height of his delusion Ayatollah Dijkstra completely lost common sense and issued a fatwa in which he declared PL/1 to be a "fatal disease". Which negatively affected the viability of the language because the whole academic atmosphere was similar to Iran and business community also listed to the proclamation of the Grand Ayatollah.
Those spikes of religious fervor damaged the language standing and helped more primitive languages with much simpler compilers such as Pascal and C to get ground on the primitive hardware that existed those days. Another advantage of Pascal was that it has a freely available complier. Despite his conversion into verification zealot, the conversion which injected grave flaws in the Pascal design (partially rectified in Modula and Turbo Pascal) , Wirth remained a master of compiler writing to his last days and he was one of the first to understand that some unessential language features can and should be sacrificed if they unnecessary complicate the compiler. In a way, he was a pioneer of "compiler driven" language design school.
The Pascal complier written by Wirth was based on recursive decent parsing and was specifically designed to make complier so fast that it can be used instead of linker (source code linking). This tremendous speed with which Pascal can be compiled (which was later demonstrated to the surprised world by Turbo Pascal) was probably the most innovative feature of the language.
Compiler from C were also much simpler then complier for comparable subset of PL/1 such as PL/M and were distributed freely with Unix source code. Creators of C discarded bogus "no reserved keywords" idea and greatly simplified the syntax of declaration of variables which removed to warts of PL/1 language not only at no cost but with considerable savings in simplicity of compiler.
But while they were cutting the language to the subset suitable for system programming they cut way too much. and those decisions hunt C and C programmers to this day. They also made some blunders in design of the syntax of the language (no mechanism for multiple closure of {} blocks with a single bracket like a: do ... end a; in PL/1 in one obvious blunder. Usage round brackets as delimiters for conditional expressions in if statements is another. Just those two errors cost C programmers immense amount of lost hours in trying to find errors that should not exist in properly designed language in the first place. they also ignored some important heuristics for catching "running string literal" errors invented in PL/1 optimizing compiler.
Structured programming dogma and verification frenzy were two first religious movements in programming, but unfortunately they were not the last. Later object orientation (OO) became fashionable with its own crowd of snake oil salesmen. Each of those splashes generated huge crowd of crooks and religious fanatics, as well as promoted corruption in computer science departments. As for computer science departments, the level of corruption from early 80th became probably pretty close to corruption of economic professions with its bunch of highly paid intellectual prostitutes or outright criminals masquerading as professors.
Brilliance of IBM design team and technical vision was demonstrated not only in the language, but even more so in the design of compilers for the language. Even the first PL/1 compiler (F-compiler) simply wiped the floor with the competition (another notable IBM achievement was optimizing compiler form Fortran -- Fortran H):
PL/I was first implemented by IBM, at its Hursley Laboratories in the United Kingdom, as part of the development of System/360. The first production PL/I compiler was the PL/I F compiler for the OS/360 Operating System, built by John Nash's team at Hursley in the UK: the runtime library team was managed by I.M.(Nobby)Clarke. The PL/I F compiler was written entirely in System/360 assembly language.[18] Release 1 shipped in 1966. OS/360 was a real-memory environment and the compiler was designed for systems with as little as 64kBytes of real storage – F being 64k in S/360 parlance. To fit a large compiler into the 44kByte memory allowed on a 64kByte machine, the compiler consisted of a control phase and a large number of compiler phases (approaching 100). The phases were brought into memory from disk, and released, one at a time to handle particular language features and aspects of compilation.
The level of diagnostics in F-compiler was good, although not perfect. A smaller subset of PL/1 was implemented in DOS/360 PL/I D-compiler which was developed at IBM Germany:
The PL/I D compiler, using 16 kilobytes of memory, was developed by IBM Germany for the DOS/360 low end operating system. It implemented a subset of the PL/I language requiring all strings and arrays to have fixed extents, thus simplifying the run-time environment. Reflecting the underlying operating system it lacked dynamic storage allocation and the controlled storage class.[21] It was shipped within a year of PL/I F.
But the real breakthrough and the real masterpieces of software engineering were IBM PL/I optimizing and checkout compilers. They are still unsurpassed pair of compilers for a very complex language despite being 40 years old.
The PL/I Optimizer and Checkout compilers produced in Hursley supported a common level of PL/I language[24] and aimed to replace the PL/I F compiler. The checkout compiler was a rewrite of PL/I F in BSL, IBM's PL/I-like proprietary implementation language (later PL/S).[18] The performance objectives set for the compilers are shown in an IBM presentation to the BCS.[25] The compilers had to produce identical results - the Checkout Compiler was used to debug programs that would then be submitted to the Optimizer. Given that the compilers had entirely different designs and were handling the full PL/I language this goal was challenging: it was achieved.
The PL/I optimizing compiler took over from the PL/I F compiler and was IBM’s workhorse compiler from the 1970s to the 1990s. Like PL/I F, it was a multiple pass compiler with a 44kByte design point, but it was an entirely new design. Unlike the F compiler it had to perform compile time evaluation of constant expressions using the run-time library - reducing the maximum memory for a compiler phase to 28 kilobytes. A second-time around design, it succeeded in eliminating the annoyances of PL/I F such as cascading diagnostics.
It was written in S/360 Macro Assembler by a team, led by Tony Burbridge, most of whom had worked on PL/I F. Macros were defined to automate common compiler services and to shield the compiler writers from the task of managing real-mode storage - allowing the compiler to be moved easily to other memory models.
The gamut of program optimization techniques developed for the contemporary IBM Fortran H compiler were deployed: the Optimizer equaled Fortran execution speeds in the hands of good programmers. Announced with the IBM S/370 in 1970, it shipped first for the DOS/360 operating system in Aug 1971, and shortly afterward for OS/360, and the first virtual memory IBM operating systems OS/VS1, MVS and VM/CMS (the developers were unaware that while they were shoehorning the code into 28kB sections, IBM Poughkeepsie was finally ready to ship virtual memory support in OS/360).
It supported the batch programming environments and, under TSO and CMS, it could be run interactively. This compiler went through many versions covering all mainframe operating systems including the operating systems of the Japanese PCMs.
The compiler has been superseded by "IBM PL/I for OS/2, AIX, Linux, z/OS" below.
The PL/I checkout compiler,[26][27] (colloquially "The Checker") announced in August 1970 was designed to speed and improve the debugging of PL/I programs. The team was led by Brian Marks. The three-pass design cut the time to compile a program to 25% of that taken by the F Compiler.
It was run from an interactive terminal, converting PL/I programs into an internal format, “H-text”. This format was interpreted by the Checkout compiler at run-time, detecting virtually all types of errors. Pointers were represented in 16 bytes, containing the target address and a description of the referenced item, thus permitting "bad" pointer use to be diagnosed.
In a conversational environment when an error was detected, control was passed to the user who could inspect any variables, introduce debugging statements and edit the source program. Over time the debugging capability of mainframe programming environments developed most of the functions offered by this compiler and it was withdrawn (in the 1990s?)
IBM did a tremendous job in developing PL/1 and, especially, PL/1 compilers. This was a good, old IBM with strong engineering core, before the current wave of outsourcing destroyed the company engineering culture.
What is interesting that despite their age PL/1 optimizing and debugging compilers for OS/360 and 370 are probably the best compliers for any language of similar complexity in existence despite being 40 years old. The real masterpieces of software engineering... Incredible achievement of IBM engineering talent. Like System 360 hardware and assembler language they stood as monuments to "good old IBM".
| Despite their age PL/1 optimizing and debugging compilers for OS/360 and 370 are probably the best compliers for any language of similar complexity in existence despite being 40 years old. The real masterpieces of software engineering... Incredible achievement of IBM engineering talent. Like System 360 hardware and assembler language they stood as monuments to "good old IBM". |
Three compilers for PL/1 (IBM debugging and optimizing compiler) and PL/C form Cornell were of such high quality that even today they are heads above average compiler in many respects including first of all the quality of diagnostic (I do not think that any other compiler managed even approach the quality of diagnostics of IBM debugging compiler and PL/C). And (for optimizing complier) the quality of code generation: for such a complex language PL/1 complier generated surprisingly fast code which was able to complete in speed with the code generated by compilers for much simpler languages such as Cobol (but not Fortran H, which was the lass of its own). In xUSSR space COBOL compilers generally proved to unable to complete with PL/1 compliers and COBOL was never widely used.
Pl/1 compliers provided very innovative high qulity complier listings. And this started with the firs F PL/1 complier.
The listing provided the nesting level and the table of variables with cross references.
It also structured messages into three five main categories (usefulness of which survived to this day):
Multics (Multiplexed Information and Computing Service) was a mainframe timesharing operating system which was designed around 1965 and used until 2000. It was often called Multix, which is formally incorrect but a shorter name. Although Multics was much derided at the time by its critics, history has shown that it was a real pioneer on OS design which introduced concepts now taken for granted and which found its way into Unix. One of the major achievement of Multics is that it used for development high level language -- and it was PL/1.
Many ideas implemented in Multics were 30-40 years ahead of their time. Ideas “discarded” in Unix were eventually added back (e.g., dynamic linking, doors were reintroduced in Solaris a few years back.)
Key ideas (see multix ) were extremely difficult to implement on primitive hardware that existed at mid 60th, so the fact that they materialized is nothing but amazing. Multics began as a research project and was an important influence on operating system development. It also pioneered the use of high-level languages for writing operating systems. It also was one of the first OS which paid serious attention o the security. As Professor Wilkes noted (iee90):
There has been some discussion of ways in which the operating system might be structured so as to facilitate, and make more systematic, the task of the inspector. One suggestion has been to restrict to an absolute minimum the amount of information that the running process can access at any given moment. This is expressed by saying that the domain of protection in which the process runs is small. Unfortunately, if everything is done in software, the frequent change of domain which this approach makes necessary leads to unacceptable loss of performance. Attention was accordingly directed to providing hardware support for domain switching.
An early suggestion, implemented in MULTICS, was to have rings of protection. The amount of information available to a process decreased as it moved from the inner to the outer rings. Unfortunately, the hierarchical model of protection which this implied is fundamentally flawed, and it was found that rings of protection were little improvement if any on the simple system of a privileged and an unprivileged mode.
PL/1 was used as system programming language, and proved to be up to the task. Due to this role it later served as a prototype of a simplified dialect that became C, which was used for writing Unix OS. Unfortunately many key ideas such as exceptions handing, built-in strings, etc were dropped as C was intended to besystem programming language. Later many of these features were "reinvented" on C++ and Java many years after they were introduced in PL/1.
Multics also was a pioneer in computer security, being essentially an opposite of Unix. Many of security innovations in Multics find its way in Unix only 30 years later. Here is how Wikipedia described the situation that existed in early 60th.
In the early 60s, IBM was struggling to define its technical direction. The company had identified a problem with its past computer offerings: incompatibility between the many IBM products and product lines. Each new product family, and each new generation of technology, forced customers to wrestle with an entirely new set of technical specifications. IBM products incorporated a wide variety of processor designs, memory architectures, instruction sets, input/output strategies, etc. (This was not, of course, unique to IBM. All computer vendors seemed to begin each new system with a "clean sheet" design.) IBM saw this as both a problem and an opportunity. The cost of software migration was an increasing barrier to hardware sales. Customers could not afford to upgrade their computers, and IBM wanted to change this.
IBM embarked on a very risky undertaking: the System/360. This product line was intended to replace IBM's diverse earlier offerings, including the IBM 7000 series, the (canceled) IBM 8000 series, the IBM 1130 series, and various other specialized machines used for scientific and other applications. The System/360 would span an unprecedented range of processing power, memory size, device support, and cost; and more important, it was based on a pledge of backward compatibility, such that any customer could move software to a new system without modification. In today's world of standard interfaces and portable systems, this may not seem such a radical goal; but at the time, it was revolutionary. Before the System/360, each computer model often had its own specific devices that could not be used with other systems. Buying a bigger CPU also meant buying new printers, card readers, tape drives, etc. With the S/360, IBM wanted to offer a huge range of computer systems, all sharing a single processor architecture, instruction set, I/O interface, and operating system. Customers would be able to "mix and match" to meet current needs; and they could confidently upgrade their systems in the future, without the need to rewrite all their software applications. IBM's focus remained on its traditional customer base: large organizations doing administrative and business data processing.
At the start of System/360 project, IBM did not fully appreciate the amount of risk involved. The System/360 ultimately gave IBM total dominance over the computer industry; but first, it nearly put IBM out of business. IBM took on one of the largest and most ambitious engineering projects in history, and in the process discovered diseconomies of scale and the mythical man-month. Extensive literature on the period, such as that by Fred Brooks, illustrate the pitfalls.
It was during the period of System/360 panic that Project MAC asked IBM to provide computers with extensive time-sharing capabilities. This was not the direction the System/360 project was going. Time-sharing wasn't seen as important to IBM's main customer base; batch processing was key. Moreover, time-sharing was new ground. Many of the concepts involved, such as virtual memory, remained unproven. (For example: At the time, nobody could explain why the troubled Manchester/Ferranti Atlas virtual memory "didn't work"[2]. This was later explained as due to thrashing, based on CP/CMS and M44/44X research.) As a result, IBM's System/360 announcement in April 1964 did not include key elements sought by the time-sharing advocates, particularly virtual memory capabilities. Project MAC researchers were crushed and angered by this decision. The System/360 design team met with Project MAC researchers, and listened to their objections; but IBM chose another path.
In February 1964, at the height of these events, IBM had launched its Cambridge Scientific Center (CSC), headed by Norm Rassmussen. CSC was to serve as the link between MIT researchers and the IBM labs, and was located in the same building with Project MAC. IBM fully expected to win the Project MAC competition, and to retain its perceived lead in scientific computing and time-sharing.
One of CSC's first projects was to submit IBM's Project MAC proposal. IBM had received intelligence that MIT was leaning toward the GE proposal, which was for a modified 600-series computer with virtual memory hardware and other enhancements; this would eventually become the GE 645. IBM proposed a modified S/360 that would include a virtual memory device called the "Blaauw Box" – a component that had been designed for, but not included in, the S/360. The MIT team rejected IBM's proposal. The S/360-67 was seen as too different from the rest of the S/360 line; MIT did not want to use a customized or special-purpose computer for Multics, but sought hardware that would be widely available. GE was prepared to make a large commitment to time-sharing, while IBM was seen as obstructive. Bell Laboratories, another important IBM customer, soon made the same decision, and rejected the S/360 for time-sharing.
Ken Thompson was one of about 25 members of the Bell Labs Technical Staff who worked on Multics in 1965-1969. He got many key ideas from the Multix system and PL/1 language in which it was written as well as the spirit of free development environment with free sharing of ideas that was created by a really brilliant computer scientist Fernando Corbato (died July 12, 2019 at the age of 93). Corbato who actually is the father of main architectural ideas used in Unix as they were borrowed from his Compatible Time-Sharing System operating system, which were available in source form) and that later became an important factor in Unix success. As Corbato noted in his Turing lecture:
The UNIX system [12] was a reaction to Multics. Even the name was a joke. Ken Thompson was part of the Bell Laboratories' Multics effort, and, frustrated with the attempts to bring a large system development under control, decided to start over.
His strategy was clear. Start small and build up the ideas one by one as he saw how to implement them well. As we all know, UNIX has evolved and become immensely successful as the system of choice for workstations. Still there are aspects of Multics that have never been replicated in UNIX.
Corbató is sometimes known for "Corbató's Law" which states: The number of lines of code a programmer can write in a fixed period of time is the same, independent of the language used.
|
Corbató's Law: The number of lines of code a programmer can write in a fixed period of time is the same, independent of the language used |
And this is a huge endorsement of complex non-orthogonal languages such as PL/1 (and partially Perl, although it went too far in non-othogonality area ;-) in comparison with more primitive and less expressive languages like C and Pascal.
Paradoxically, PL/1 played a role of freeware at least in one country ;-). And in this environment it quickly became the dominant programming language on mainframes in the USSR, far outpacing Cobol and Fortran. Which still dominated the mainframe arena in the USA and other Western countries.
So here analogy with Perl hold perfectly. PL/1 dominated despite the fact the Soviet IBM 360/370 clones (called EC -- Russian abbreviation of "Uniform System of Computers") were much less powerful (and far less reliable) that Western counterparts.
PL/C was a brilliant implementation of subset of PL/1 for teaching purposes at Cornell University. It was written in early 1970s and has diagnostic capabilities that were comparative with the capabilities of IBM Pl/1 complier, beating it in some areas. The PL/C compiler had the unusual capability of never failing to compile any program, through the use of extensive automatic correction of many syntax errors and by converting any remaining syntax errors to output statements. Cornell's compiler for PL/1 subset was based on its earlier CUPL compiler, and it was widely used in college-level programming courses. The two researchers and academic teachers who designed PL/C were Richard W. Conway and Thomas R. Wilcox. They submitted the famous article "Design and implementation of a diagnostic compiler for PL/I" published in the Communications of ACM in March 1973, pages 169-179.
PL/C eliminated some of the more complex features of PL/I, and added extensive debugging and error recovery facilities. PL/C is a subset of PL/I. A program that runs without error under the PL/C compiler should run under IBM PL/I compiler and produce the same results, unless certain incompatible diagnostic features were used.
Several dozem of good PL/C related books were published and it was used for teaching introductory classes for more then a decade.
When personal computers start their triumphal conquest of the world, PL/1 enjoyed a short lived renaissance due to valiant efforts of Gary Kindal. PL/M was a subset of PL/1 very similar to IBM DOS compiler subset that gained popularity in CP/M world. But as CP/M was overtaken by PC DOS/MS DOS, PL/M have had fallen into sidelines too. Both Turbo Pascal and C had eaten PL/M lunch mainly due to availability of cheaper compilers and in case of Turbo Pascal an innovative IDE (which actually was re-implemented for C in a form of Turbo C too -- giving C the same huge edge as Pascal). Here again the complexity (and the costs of ) compilers were huge negative factor. Here is additional info from Wikipedia:
Here some additional information about this once very popular compiler from a subset of PL/1 which was close to subset of Pl/1 implemented by IBM DOS compiler (Gary Kildall - CP-M, Digital Research and GEM )
Gary Kildall is someone who had most influence during the early days of the microcomputer revolution. Because of the way history unfolded not much of his legacy is visible today - but he was an important pioneer and one of the first people to take microprocessors seriously.
It is tempting to compare him with Bill Gates - they both produced computer language implementations, operating systems and large companies - but the similarity is only superficial.
Bill Gates was an enthusiast, a garage entrepreneur, a stylish programmer; very much the product of the computer revolution of the 70s. Kildall on the other hand was less of an enthusiast, more of an outsider and an onlooker as the revolution progressed.
Gary Kildall (1942-1994)
Kildall was born and grew up in Seattle, Washington, where his family operated a seafaring school. At the University of Washington he initially studied mathematics and it was here he became interested in computer technology. When he graduated he was drafted into the Navy where he taught at the Naval Postgraduate School (NPS).
He received his PhD in computer science in 1972 at a time when the first microcomputers were making their appearance. He then resumed his teaching computer science and programming in particular at NPS, preaching the then reasonably new creed of structured, modular, top-down programming. This slightly academic view of programming and background might help to explain some of the strange events in his career. Like all academics Kildall worked on various `real' projects including his lucky break - PL/M.
At the time microcomputers looked very underpowered compared to the mainframe and mini computers that most academics had access to. The general attitude of the computer professional towards the microcomputer was "what can you do with it?" They looked more like electronic toys.
The enthusiasts with no access to more powerful computers looked at them rather differently because they were the only computers that they were likely to get their hands on and in this case the question was how rather than what.
Gary Kildall was involved in a project (1972) for Intel to develop a compiler for a highish level language for the 8080 - the first in the family of processors that leads directly to today's multicore Pentium designs. The language was PL/M, fancifully named to sound like IBM's PL/1 super language.
PL/M and later PL/I-G compiler came out from Digital Research in 1980 was the best compiler built for the Intel chip It was an excellent language for programming applications, and for most applications assembly language programmers could not do better than the machine code it produced.
Later PL/1 was ported to OS/2. It happened in 1992. Here is how this event was described in Wikipedia
In a major revamp of PL/I, IBM Santa Teresa in California launched an entirely new compiler in 1992. The initial shipment was for OS/2 and included most ANSI-G features and many new PL/I features.[36] Subsequent releases covered additional platforms (MVS, VM, OS/390, AIX and Windows)[37] and continued to add functions to make PL/I fully competitive with other languages offered on the PC (particularly C and C++) in areas where it had been overtaken. The corresponding “IBM Language Environment" supports inter-operation of PL/I programs with Database and Transaction systems, and with programs written in C, C++, and COBOL, the compiler supports all the data types needed for intercommunication with these languages.
The PL/I design principles were retained and withstood this major extension comprising several new data types, new statements and statement options, new exception conditions, and new organization of program source. The resulting language is a compatible super-set of the PL/I Standard and of the earlier IBM compilers. Major topics added to PL/I were:
- New attributes for better support of object-oriented programming – the
DEFINE ALIAS,ORDINAL, andDEFINE STRUCTUREstatement to introduce user-defined types, theHANDLElocator data type, theTYPEdata type itself, theUNIONdata type, and built-in functions for manipulating the new types.- Additional data types and attributes corresponding to common PC data types (e.g.
UNSIGNED,VARYINGZ).- Improvements in readability of programs – often rendering implied usages explicit (e.g.
BYVALUEattribute for parameters)- Additional structured programming constructs.
- Interrupt handling additions.
- Compile time preprocessor extended to offer almost all PL/I string handling features and to interface with the Application Development Environment
This port had died with OS/2. IBM port to AIX of OS/2 PL/1 compiler was the last in this line of PL/1 compiler development and I think that IBM still sells it. This is a kind of "last of Mohican" presence of PL/1 outside of mainframes. There was also a much later port from Iron Spring for OS/2 and later Linux which was introduced in 2007.
To write a decent compiler for PL/1 was not easy. Along with natural complexity of the language there were couple of features that unnecessary complicated the creation of compiler:
Stings implementation was an example of premature optimization: each string was prefixed by its length, which make is a data structure and limited maximum length of the string to two limits 256 bites (one byte prefix) and 64K (two bytes prefix).
Due to those shortcomings and the compete absence of high quality portable open source compilers PL/1 popularity suffered greatly.
|
Complex non-orthogonal programming language rarely became hugely popular. Popularity is reserved for simplistic, dumb-down languages. Cobol, Basic, Pascal and Java popularity are primary examples here. All of them are dull uninventive languages designed for novices (with Pascal explicitly designed as for teaching programming at universities). PL/1 was the first complex non-orthogonal language that managed to achieve world wide popularity. |
Bubble Sort
Building a header of the report (STROSH)
neatxt
neatpl
NOTE: Level of diagnostic of Checkout complier (aka Checker) was nothing but amazing. To understand the level of this achievement you need to use it.
The key problems with PL/1 were always availability of high quality free or reasonably cheap compilers. Even now this problem is not solved. Here are some options (see PL-I Frequently Asked Questions (FAQ) for more up-to-date info about PL/1 compilers available):
Download the free PL/1 compiler from Iron Spring as a zipped tar file - unpack it using gzip -d and tar xvf within your own PL1 sub folder (directory). within the pli-0.9.1 sub folder, run make install as superuser, then make your own code sub directory. Copy the Makefile from samples, edit this file to call the name of your own pl/1 program. Run make to compile it (still within your own code sub - dir ). Thanks for watching
The IBM PL/I compilers deliver innovative and open solutions to professional programmers for rapidly exploiting network middleware while developing, extending and managing scalable business and Web applications. These compatible, cross-platform, cross-product compilers support z/OS®, VM, VSE/ESA®, AIX®, and Microsoft® Windows®. They also help you use your existing PL/I code to upgrade your applications with the newest technologies. .
PLI-80 BINARY : 146K This is the PLI compiler. It is very compatible with the IBM PLI compiler used on the 360. The only functions I found missing were DATE and TIME, which were easy to fake out.
A good free guides to PL/1 is available from IBM:
Almost free old books devoted to PL/1 are still available on Amazon with average price of $1 or so. For example
Paradoxically PL/1 was never a success in the USA. In Europe PL/1 was used extensively in both business and scientific applications. In the USSR and Eastern Europe on mainframes PL/1 decimated Cobol as the language of choice for writing business applications.
However, it's popularity has drastically declined with the introduction of personal computers. For some reason C (which for many programming tasks is inferiors to PL/1) and Pascal (which was in comparison with PL/1 a toy language) became more popular. That might be connected with the absence of low cost compilers for PL/1 although its dialect PL/M enjoyed some popularity before being displaced with C.
One reason for this situation might be that programming in complex, non-orthogonal languages like PL/1 requires higher level of abilities and higher level of sophistication (as in such languages there are several ways of accomplishing a task) then in simpler languages and that this limitation of human abilities gave simpler languages tremendous boost.
In scripting languages PL/1 influence can be found in REXX and Perl, especially in the latter. Perl is another complex non-orthogonal language which like PL/1 played tremendous innovative role but later was superseded by various derivatives more simpler derivatives like PHP Python and Ruby; two of the latter also tried to milk OO fashion...
These are still a few companies were PL/1 is widely used (almost exclusively on mainframes). Among them is Ford.
See also PL-I Frequently Asked Questions (FAQ)
|
|
Switchboard | ||||
| Latest | |||||
| Past week | |||||
| Past month | |||||
Jul 17, 2021 | www.linkedin.com
Development was easier in the days of classical CICS, where all the logic was managed by a single mainframe computer and 3270 clients were responsible for nothing except displaying output and responding to keystrokes. But that's no longer adequate when smart phones and PC's are more powerful than mainframes of old, and our task is to develop systems that can integrate large shared databases with local processing to provide the modern systems that we need. This needs web services, but development of distributed systems with COBOL, Java, C#, and similar technology is difficult.
Since 2015 MANASYS Jazz has been able to develop CICS web services, but it remained difficult to develop client programs to work with them. Build 16.1 (December 2020) was a major breakthrough, offering integrated development of COBOL CICS web services for the mainframe, and C# client interfaces that make client development as easy as discovering properties and methods with Intellisense.
Build 16.2 (January 2021) supported services returning several records. We'd found that each request/response took a second or two, whether it was returning 1 or many records, but the interface could page forward and back instantly within the list of returned records. Build 16.2 also offered easy addition of related-table data, and interfaces for VSAM as well as DB2 web services. Build 16.3 (June 2021) takes a further step, adding services and interfaces for parent-child record collections, for example a Department record with the list of Employees who work there.
Our video "Bridging Two Worlds" has been updated to demonstrate these features. See how easy it is to create a web service and related client logic that will display and update one or many records at a time. See how MANASYS controls updating with CICS-style pseudo-locking, preventing invalid updates automatically. See how easily MANASYS handles data from many records at a time, resulting in clean and efficient service architecture.
Robert Barnes,
CEO, Jazz Software Ltd
Birkenhead, Auckland 0626, New Zealand
Mobile +64 27 4592702
Skype Robert.barnes3
Oct 01, 2019 | veekaybee.github.io
In 1976, after eight years in the Soviet education system, I graduated the equivalent of middle school. Afterwards, I could choose to go for two more years, which would earn me a high school diploma, and then do three years of college, which would get me a diploma in "higher education."
Or, I could go for the equivalent of a blend of an associate and bachelor's degree, with an emphasis on vocational skills. This option took four years.
I went with the second option, mainly because it was common knowledge in the Soviet Union at the time that there was a restrictive quota for Jews applying to the five-year college program, which almost certainly meant that I, as a Jew, wouldn't get in. I didn't want to risk it.
My best friend at the time proposed that we take the entrance exams to attend Nizhniy Novgorod Industrial and Economic College. (At that time, it was known as Gorky Industrial and Economic College - the city, originally named for famous poet Maxim Gorky, was renamed in the 1990s after the fall of the Soviet Union.)
They had a program called "Programming for high-speed computing machines." Since I got good grades in math and geometry, this looked like I'd be able to get in. It also didn't hurt that my aunt, a very good seamstress and dressmaker, sewed several dresses specifically for the school's chief accountant, who was involved in enrollment decisions. So I got in.
What's interesting is that from the almost sixty students accepted into the program that year, all of them were female. It was the same for the class before us, and for the class after us. Later, after I started working the Soviet Union, and even in the United States in the early 1990s, I understood that this was a trend. I'd say that 70% of the programmers I encountered in the IT industry were female. The males were mostly in middle and upper management.
My mom's code notebook, with her name and "Macroassembler" on it.
We started what would be considered our major concentration courses during the second year. Along with programming, there were a lot of related classes: "Computing Appliances and Their Organization", "Electro Technology", "Algorithms of Numerical Methods," and a lot of math that included integral and differential calculations. But programming was the main course, and we spent the most hours on it.
Notes on programming - Heading is "Directives (Commands) for job control implementation", covering the ABRT command
In the programming classes, we studied programming the "dry" way: using paper, pencil and eraser. In fact, this method was so important that students who forgot their pencils were sent to the main office to ask for one. It was extremely embarrassing, and we learned quickly not to forget them.
Paper and pencil code for opening a file in Macroassembler
Every semester we would take a new programming language to learn. We learned Algol, Fortran,and PL/1. We would learn from simplest commands to loop organization, function and sub-function programming, multi-dimensional array processing, and more.
After mastering the basics, we would take exams, which were logical computing tasks to code in this specific language.
At some point midway through the program, our school bought the very first physical computer I ever saw : the Nairi. The programming language was AP, which was one of the few computer languages with Russian keywords.
Then, we started taking labs. It was terrifying experience. You had to type your program in entering device which basically was a typewriter connected to a huge computer. The programs looked like step-by-step instructions, and if you made even one mistake you had to start all over again. To code a solution for a linear algebraic equation usually would take 10 - 12 steps.
Program output in Macroassembler ("I was so creative with my program names," jokes my mom.)
Our teacher used to go for one week of "practice work and curriculum development," to a serious IT shop with more advanced machines every once in a while. At that time, the heavy computing power was in the ES Series, produced by Soviet bloc countries.
These machines were clones of the IBM 360. They worked with punch cards and punch tapes. She would bring back tons of papers with printed code and debugging comments for us to learn in classroom.
After two and half years of rigorous study using pencil and paper, we had six months of practice. Most of the time it was one of several scientific research institutes existed in Nizhny Novgorod. I went to an institute that was oriented towards the auto industry.
I graduate with title "Programmer-Technician". Most of the girls from my class took computer operator jobs, but I did not want to settle. I continued my education at Lobachevsky State University , named after Lobachevsky , the famous Russian mathematician. Since I was taking evening classes, it took me six years to graduate.
I wrote a lot about my first college because now looking back I realize that this is where I really learned to code and developed my programming skills. At the State University, we took a huge amount of unnecessary courses. The only useful one was professional English. After this course I could read technical documentation in English without issues.
My final university degree was equivalent to a US master's in Computer Science. The actual major was called "Computational Mathematics and Cybernetics".
In total I worked for about seven years in the USSR as computer programmer, from 1982 to 1989. Technology changed rapidly, even there. I started out writing programs on special blanks for punch card machines using a Russian version of Assembler. To maximize performance, we would leave stacks of our punch cards for nightly processing.
After a couple years, we got terminals with keyboards. First they were installed in the same room where main computer was. Initially, there were not enough terminals and "machine time" was evenly divided between all of the programmers during the day.
Then, the terminals started to appear in the same room where programmers were. The displays were small, with black background and green font. We were now working in the terminal.
The languages were also changing. I switched to C and had to get hands-on training. I did not know then, but I picked profession where things are constantly moving. The most I've ever worked with the same software was for about three years.
In 1991, we emigrated to the States. I had to quit my job two years before to avoid any issues with the Soviet government. Every programmer I knew had to sign a special form commanding them to keep state secrets. Such a signature could prevent us from getting exit visas.
When I arrived in the US, I worried I had fallen behind. To refresh my skills and to become more marketable, I had to take programming course for six months. It was the then-popular mix of COBOL, DB2, JCL etc.
The main differences between USA and the USSR was the level at which computers were incorporated in every day life. In the USSR, they were still a novelty. There were not a lot of practical usage. Some of the reasons were planed organization of economy, politicized approach to science. Cybernetics was considered "capitalist" discovery and was in exile in 1950s. In the United States, computers were already widely in use, and even in consumer settings.
The other difference is gender of this profession. In the United States, it is more male-dominated. In Russia as I was starting my professional life, it was considered more of a female occupation. In both programs I studied , girls represented 100% of the class. Guys would go for something that was considered more masculine. These choices included majors like construction engineering and mechanical engineering.
Now, things have changed in Russia. Average salary for software developer in Moscow is around $21K annually, versus $10K average salary for Russia as a whole. It, like in the United States, has become a male-dominated field.
In conclusion, I have to say I picked the good profession to be in. Although I constantly have to learn new things, I've never had to worry about being employed. When I did go through a layoff, I was able to find a job very quickly. It is also a good paying job. I was very lucky compared to other immigrants, who had to study programming from scratch.
Sep 21, 2019 | www.scriptol.com
1948
1949
- Plankalkül. First high-level language. The date is that of the first public description.
1951
- Short Code.
1952
- A-0 (starting work for Math-Matic).
1955
- Autocode.
1956
- FLOW-MATIC. By Grace Hopper, first language with words.
1957
- IPL.
1958
- Fortran.
- Math-Matic.
1959
- Fortran II.
- Lisp, work begins by John Mc Carthy at MIT..
- ALGOL 58 also called IAL (International Algorithmic Language). Original specification by a comitee of European and American computer scientists.
- IAL.
- UNCOL. First intermediate language for a virtual machine.
1960
- Lisp 1.5.
- COBOL, work begins.
1962
- ALGOL 60. Revision of ALGOL 58, and first implementation.
- APL, work begins.
- COBOL defined.
- First JIT functions used for Lisp.
1963
- APL implemented.
- Fortran IV appears.
- SNOBOL, work begins.
- Simula.
1964
- ALGOL 60 is revised.
- CPL. Universities of Cambridge and of London. Extended version of Algol 60. Predecessor of BCPL.
- PL/1, work begins.
- Joss.
- Apl-360 is implemented.
- Basic.
- PL/1.
- COWSEL. Renamed POP-1 in 1966, sort of Lisp without parenthesis.
- MATHLAB. Became popular since MATHLAB 68.
- ... ... ...
Jul 09, 2017 | tech.slashdot.org
(multicians.org)"The seminal operating system Multics has been reborn," writes Slashdot reader doon386 :
The last native Multics system was shut down in 2000 . After more than a dozen years in hibernation a simulator for the Honeywell DPS-8/M CPU was finally realized and, consequently, Multics found new life... Along with the simulator an accompanying new release of Multics -- MR12.6 -- has been created and made available. MR12.6 contains many bug and Y2K fixes and allows Multics to run in a post-Y2K, internet-enabled world. Besides supporting dates in the 21st century, it offers mail and send_message functionality, and can even simulate tape and disk I/O. (And yes, someone has already installed Multics on a Raspberry Pi.)
Version 1.0 of the simulator was released Saturday, and Multicians.org is offering a complete QuickStart installation package with software, compilers, install scripts, and several initial projects (including SysDaemon, SysAdmin, and Daemon).
Plus there's also useful Wiki documents about how to get started, noting that Multics emulation runs on Linux, macOS, Windows, and Raspian systems. The original submission points out that "This revival of Multics allows hobbyists, researchers and students the chance to experience first hand the system that inspired UNIX."
www.sorehands.com ( 142825 ) , Sunday July 09, 2017 @01:47AM ( #54772267 ) Homepage
I used it at MIT in the early 80s. ( Score: 4 , Informative)Gravis Zero ( 934156 ) , Sunday July 09, 2017 @02:10AM ( #54772329 )I was a project administrator on Multics for my students at MIT. It was a little too powerful for students, but I was able to lock it down. Once I had access to the source code for the basic subsystem (in PL/1) I was able to make it much easier to use. But it was still command line based.
A command line, emails, and troff. Who needed anything else?
It's not the end! ( Score: 4 , Interesting)Tom ( 822 ) , Sunday July 09, 2017 @04:16AM ( #54772487 ) Homepage JournalConsidering that processor was likely made with the three micrometer lithographic process, it's quite possible to make the processor in a homemade lab using maskless lithography. Hell, you could even make it NMOS if you wanted. So yeah, emulation isn't the end, it's just another waypoint in bringing old technology back to life.
Multics ( Score: 5 , Interesting)nuckfuts ( 690967 ) , Sunday July 09, 2017 @02:00PM ( #54774035 )The original submission points out that "This revival of Multics allows hobbyists, researchers and students the chance to experience first hand the system that inspired UNIX."More importantly: To take some of the things that Multics did better and port them to Unix-like systems. Much of the secure system design, for example, was dumped from early Unix systems and was then later glued back on in pieces.
Influence on Unix ( Score: 4 , Informative)Shirley Marquez ( 1753714 ) , Monday July 10, 2017 @12:44PM ( #54779281 ) HomepageFrom here [wikipedia.org]...
The design and features of Multics greatly influenced the Unix operating system, which was originally written by two Multics programmers, Ken Thompson and Dennis Ritchie. Superficial influence of Multics on Unix is evident in many areas, including the naming of some commands. But the internal design philosophy was quite different, focusing on keeping the system small and simple, and so correcting some deficiencies of Multics because of its high resource demands on the limited computer hardware of the time.
The name Unix (originally Unics) is itself a pun on Multics. The U in Unix is rumored to stand for uniplexed as opposed to the multiplexed of Multics, further underscoring the designers' rejections of Multics' complexity in favor of a more straightforward and workable approach for smaller computers. (Garfinkel and Abelson[18] cite an alternative origin: Peter Neumann at Bell Labs, watching a demonstration of the prototype, suggested the name/pun UNICS (pronounced "Eunuchs"), as a "castrated Multics", although Dennis Ritchie is claimed to have denied this.)
Ken Thompson, in a transcribed 2007 interview with Peter Seibel[20] refers to Multics as "...overdesigned and overbuilt and over everything. It was close to unusable. They (i.e., Massachusetts Institute of Technology) still claim it's a monstrous success, but it just clearly wasn't." He admits, however, that "the things that I liked enough (about Multics) to actually take were the hierarchical file system and the shell! a separate process that you can replace with some other process."
A hugely influential failure ( Score: 2 )The biggest problem with Multics was GE/Honeywell/Bull, the succession of companies that made the computers that it ran on. None of them were much good at either building or marketing mainframe computers.
So yes, Multics was a commercial failure; the number of Multics systems that were sold was small. But in terms of moving the computing and OS state of the art forward, it was a huge success. Many important concepts were invented or popularized by Multics, including memory mapped file I/O, multi-level file system hierarchies, and hardware protection rings. Security was a major focus in the design of Multics, which led to it being adopted by the military and other security-conscious customers.
by R. A. FREIBURGHOUSE
General Electric Company
Cambridge, MassachusettsINTRODUCTION
The Multics PL/1 compiler is in many respects a "second generation" PL/1 compiler. It was built at a time when the language was considerably more stable and well defined than it had been when the first compilers were built [1,2]. It has benefited from the experience of the first compilers and avoids some of the difficulties which they encountered. The Multics compiler is the only PL/1 compiler written in PL/1 and is believed to be the first PL/1 compiler to produce high speed object code.
The language
The Multics PL/1 language is the language defined by the IBM "PL/1 Language Specifications" dated March 1968. At the time this paper was written most language features were implemented by the compiler but the run time library did not include support for input and output, as well as several lesser features. Since the multi-tasking primitives provided by the Multics operating system were not well suited to PL/1 tasking, PL/1 tasking was not implemented. Inter-process communication (Multics tasking) may be performed through calls to operating system facilities.
The system environment
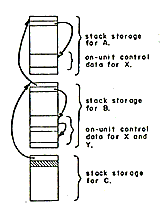
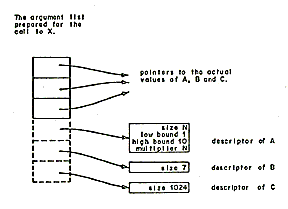
The compiler and its object programs operate within the Multics operating system. [3.4,5] The environment provided by this system includes a virtual two dimensional address space consisting of a large number of segments. Each segment is a linear address space whose addresses range from 0 to 64K. The entire virtual store is supported by a paging mechanism, which is invisible to the program. Each program operating in this environment consists of two segments: a text segment containing a pure re-entrant procedure, and a linkage segment containing out-references (links), definitions (entry names), and static storage local to the program. The text segment of each program is sharable by all other users on the system. Linking to a called program is normally done dynamically during program execution.
Implementation techniques
The entire compiler and the Multics operating system were written in EPL, a large subset of PL/1 containing most of the complex features of the language. The EPL compiler was built by a team headed by M. D. McIlroy and R. Morris of Bell Telephone Laboratories. Several members of the Multics PL/1 project modified the original EPL compiler to improve its object code performance, and utilized the knowledge acquired from this experience in the design of the Multics PL/1 compiler. EPL and Multics PL/1 are sufficiently compatible to allow the Multics PL/1 compiler to compile itself and the operating system.
The Multics PL/1 compiler was built and de-bugged by four experienced system programmers in 18 months. All program preparation was done on-line using the CTSS time-sharing System at MIT, Most de-bugging was done in a batch mode on the GE645, but final de-bugging was done on-line using Multics.
The extremely short development time of 18 months was made possible by these powerful tools. The same design programmed in a macro-assembly language using card input and batched runs would have required twice as much time, and the result would have been extremely unmanageable.
Design objectives
The project's design decisions and choice of techniques were influenced by the following objectives:
- A correct implementation of a reasonably complete PL/1 language.
- A compiler which produced relatively fast object code for all language constructs. For similar language constructs, the object code was expected to equal or exceed that produced by most Fortran or COBOL compilers.
- Object program compatibility with EPL object programs and other Multics languages.
- An extensive compile time diagnostic facility.
- A machine independent compiler capable of bootstrapping itself onto other hardware.
The compiler's size and speed were considered less important than the above mentioned objectives. Each phase of the original compiler occupies approximately 32K, but after the compiler bas compiled itself that figure will be about 24K. The original compiler was about twice as slow as the Multics Fortran compiler. The bootstrapped version of the PL/1 compiler is expected to be considerably faster than the original version but it will probably not equal the speed of Fortran.
An overview of the compiler
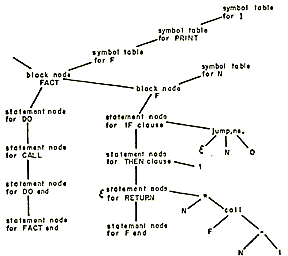
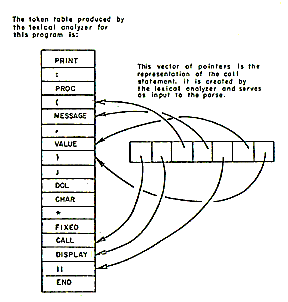
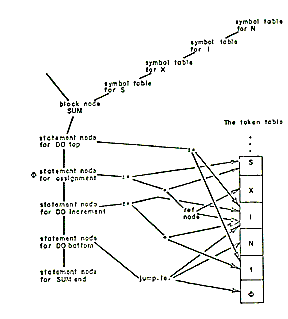
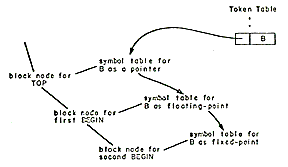
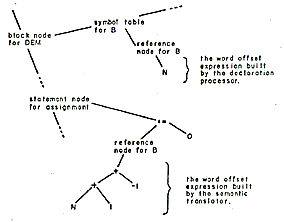
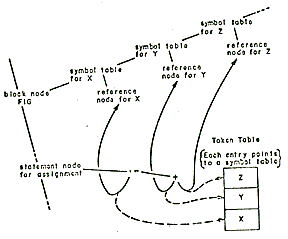
The Multics PL/1 compiler is designed along traditional lines. It is not an interactive compiler nor does it perform partial compilations. The compiler translates PL/1 external procedures into relocatable binary machine code which may be executed directly or which may be bound together with other procedures compiled by any Multics language processor.
The notion of a phase is particularly useful when discussing the organization of the Multics PL/1 compiler. A phase is a set of procedures which performs a major logical function of compilation, such as syntactic analysis. A phase is not necessarily a memory load or a pass over some data base although it may, in some cases, be either or both of these things.
The dynamic linking and paging facilities of the Multics environment have the effect of making available in virtual storage only those specific pages of those particular procedures which are referenced during an execution of the compiler. A phase of the Multics PL/1 compiler is therefore only a logical grouping of procedures which may call each other. The PL/1 compiler is organized into five phases: Syntactic Translation, Declaration Processing, Semantic Translation, Optimization, and Code Generation.
The internal representation
The internal representation of the program being compiled serves as the interface between phases of the compiler. The internal representation is organized into a modified tree structure (the program tree) consisting of nodes which represent the component parts of the program, such as blocks, groups, statements, operators, operands, and declarations. Each node may be logically connected to any number of other nodes by the use of pointers.
Each source program block is represented in the program tree by a block node which has two lists connected to it: a statement list and a declaration list. The elements of the declaration list are symbol table nodes representing declarations of identifiers within that block. The elements of the statement list are nodes representing the source statements of that block. Each statement node contains the root of a computation tree which represents the operations to be performed by that statement. This computation tree consists of operator nodes and operand nodes.
The operators of the internal representation are n-operand operators whose meaning closely parallels that of the PL/1 source operators. The form of an operand is changed by certain phases, but operands generally refer to a declaration of some variable or constant. Each operand also serves as the root of a computation tree which describes the computations necessary to locate the item at runtime.
This internal representation is machine independent in that it does not reflect the instruction set, the addressing properties, or the register arrangement of the GE645. The first four phases of the compiler are also machine independent, since they deal only with this machine independent internal representation. Figure 1 shows the internal representation of a simple program.
FACT: PROC; DCL I FIXED, PRINT ENTRY, F ENTRY RETURNS(FIXED), N INT; DO I = 1 TO 10; CALL PRINT("Factorial is", F(I)); END; F: PROC (N) FIXED; DCL N FIXED; IF N = 0 THEN RETURN(1); RETURN(N*F(N-1)); END F; END FACT;
Figure 1-The internal representation of a program. The example is greatly simplified. Only the statements of procedure F are shown in detail.
Syntactic translation
Syntactic analysis of PL/1 programs is slightly more difficult than syntactic analysis of other languages such as Fortran. PL/1 is a larger language containing more syntactic constructs, but it does not present any significantly new problems. The syntactic translator consists of two modules called the lexical analyzer and the parse.
Lexical analysis
The lexical analyzer organizes the input text into groups of tokens which represent a statement. It also creates the source listing file and builds a token table which contains the source representation of all tokens in the source program. A token is an identifier, a constant, an operator or a delimiter. The lexical analyzer is called by the parse each time the parse wants a new statement.
The lexical analyzer is an approximation to a finite state machine. Since the lexical analyzer must produce output as well as recognize tokens, action codes are attached to the state transitions of the finite state machine. These action codes result in the concatenation of individual characters from the output until a recognized token is formed. Constants are not converted to their internal format by the lexical analyzer. They are converted by the semantic translator to a format which depends on the context in which the constant appears.
The token table produced by the lexical analyzer contains a single entry for each unique token in the source program. Searching of the token table is done utilizing a hash coded scheme which provides quick access to the table. Each token table entry contains a pointer which may eventually point to a declaration of the token. For each statement, the lexical analyzer builds a vector of pointers to the tokens which were found in the statement. This vector serves as the input to the parse. Figure 2 shows a simple example of lexical analysis.
PRINT: PROC(MESSAGE, VALUE); DCL MESSAGE CHAR(*), VALUE FIXED; CALL DISPLAY(MESSAGE || VALUE); END;
Figure 2-The output of the lexical analyzerThe parse
The parse consists of a set of possibly recursive procedures, each of which corresponds to a syntactic unit of the language. These procedures are organized to perform a top down analysis of the source program. As each component of the program is recognized, it is transformed into an appropriate internal representation. The completed internal representation is a program tree which reflects the relationships between all of the components of the original source program. Figure 3 shows the results of the parse of a simple program.
Figure 3-The output of the parse
Syntactic contexts which yield declarative information are recognized by the parse, and this information is passed to a module called the context recorder which constructs a data base containing this information. Declare statements are parsed into partial symbol table nodes which represent declarations.
The problem of backup
The top down method of syntactic analysis is used because of its simplicity and flexibility. The use of a simple statement recognition algorithm made it possible to eliminate all backup. The statement recognizer identifies the type of each statement before the parse of that statement is attempted. The algorithm used by this procedure first attempts to recognize assignment statements using a left to right scan which looks for token patterns which are roughly analogous to X = or X ( ) =. If a statement is not recognized as an assignment, its leading token is matched against a keyword list to determine the statement type. This algorithm is very efficient and is able to positively identify all legal statements without requiring keywords to be reserved.
Declaration processing
PL/1 declaration processing is complicated by the great variety of data attributes and by the context sensitive manner in which they are derived. Two modules, the context processor and the declaration processor, process declarative information gathered by the parse.
The context processor
The context processor scans the data base containing contextually derived attributes produced during the parse by the context recorder. It either augments the partial symbol table created from declare statements or creates new declarations having the same format as those derived from declare statements. This activity creates contextual and implicit declarations.
The declaration processor
The declaration processor develops sufficient information about the variables of the program so that they may be allocated storage, initialized and accessed by the program's operators. It is organized to perform three major functions: the preparation of accessing code, the computation of each variable's storage requirements, and the creation of initialization code.
The declaration processor is relatively machine independent. All machine dependent characteristics, such as the number of bits per word and the alignment requirements of data types, are contained in a table. All computations or statements produced by the declaration processor have the same internal representation as source language expressions or statements. Later phases of the compiler do not distinguish between them.
The use of based references by the declaration processor
The concept of a based reference is useful to the understanding of PL/1 data accessing and the implementation of a number of language features. A based declaration of the form. DCL A BASED is referenced by a based reference of the form p -> A, where p is a pointer to the storage occupied by a value whose description is given by the declaration of A. Multiple instances of data having the characteristics of A can be referenced through the use of unique pointers, i.e. Q -> A, R -> A, etc.
The declaration processor implements a number of language features by transforming them into suitable based declarations. Automatic data whose size is variable is transformed into a based declaration. For example the declaration:
DCL A(N) AUTO;becomesDCL A(N) BASED(P);where: p is a compiler produced pointer which is set upon entry to the declaring block.Based declarations are also used to implement parameters. For example.
X: PROC (C); DCL C;becomesX: PROC (P); DCL C BASED(P);where: p is a pointer which points to the argument corresponding to the parameter C.
Data accessing
The address of an item of PL/1 data consists of three basic parts: a pointer to some storage location, a word offset from that location and a bit offset from the word offset. Either or both offsets may be zero. The term "word" is understood to refer to the addressable unit of a computer's storage.
Example 1
DCL A AUTO;The address of A consists of a pointer to the declaring block's automatic storage, a word offset within that automatic storage and a zero bit offset.
Example 2
DCL 1 S BASED (P), 2 A BIT(5), 2 B BIT(N);When referenced by P -> B, the address of B is a pointer P, a zero word offset and a bit offset of 5. The word offset may include the distance from the origin of the item's storage class, as was the case with the first example, or it may be only the distance from the level-one containing structure, as it was in the last example. The term "level-one" refers to all variables which are not contained within structures. Subscripted array element references, A(K, J), or sub-string references, SUBSTR(X, K, J), may also be expressed as offsets.
Offset expressions
The declaration processor constructs offset expressions which represent the distance between an element of a structure and the data origin of its level-one containing structure. If an offset expression contains only constant terms, it is evaluated by the declaration processor and results in a constant addressing offset. If the offset expression contains variable terms, the expression results in the generation of accessing instructions in the object program. The discussion which follows describes the efficient creation of these offset expressions.
Given a declaration of the form:
DCL 1 S, 2 A BIT(M), 2 B BIT(5), 2 C FLOAT;The offset of A is zero, the offset of B is M bits, and the offset of C is M + 5 bits rounded upward to the nearest word boundary.
In general, the offset of the nth item in a structure is:
bn(cn-l(sn-1) + bn-1(cn-2(sn-2) + bn-2
(...b3(c2(s2) + b2(c1(s1)))...)))
where: bk is a rounding function which expresses the boundary requirement of the kth item. sk is the size of the kth item. ck is the conversion factor necessary to convert sk to some common units such as bits.
The declaration processor suppresses the creation of unnecessary conversion functions (ck) and boundary functions (bk) by keeping track of the current units and boundary as it builds the expression. As a result the offset expressions of the previous example do not contain conversion functions and boundary functions for A and B.
During the construction of the offset expression, the declaration processor separates the constant and variable terms so that the addition of constant terms is done by the compiler rather than by accessing code in the object program. The following example demonstrates the improvement gained by this technique.
DCL 1 S, 2 A BIT(5), 2 B BIT(K), 2 C BIT(6), 2 D BIT(10);The offset of D is K+11 instead of 5+K+6.
The word offset and the bit offset are developed separately. Within each offset, the constant and variable parts are separated. These separations result in the minimization of additions and unit conversions. If the declaration contains only constant sizes, the resulting offsets are constant. If the declaration contains expressions, then the offsets are expressions containing the minimum number of terms and conversion factors. The development of size and offset expressions at compile time enables the object program to access data without the use of data descriptors or "dope vectors." [6] Most existing PL/1 implementations make extensive use of such descriptors to access data whose size or offsets are variable. Unless these descriptors are implemented by hardware, their use results in rather inefficient object code. The Multics PL/1 strategy of developing offset expressions from the declarations results in accessing code similar to that produced for subscripted array references. This code is generally more efficient than code which uses descriptors.
In general, the offset expressions constructed by the declaration processor remain unchanged until code generation. Two cases are exceptions to this rule: subscripted array references, A(K,J), and sub-string references, SUBSTR(X,K,J). Each subscripted reference or sub-string reference is a reference to a unique sub-datum within the declared datum and, therefore, requires a unique offset. The semantic translator constructs these unique offsets using the subscripts from the reference and the offset prepared by the declaration processor.
Allocation
The declaration processor does not allocate storage for most classes of data, but it does determine the amount of storage needed by each variable. Variables are allocated within some segment of storage by the code generator. Storage allocation is delayed because, during semantic translation and optimization, additional declarations of constants and compiler created variables are made.
Initialization
The declaration processor creates statements in the prologue of the declaring block which will initialize automatic data. It generates DO statements, IF statements and assignment statements to accomplish the required initialization.
The expansion of the initial attribute for based and controlled data is identical to that for automatic data except that the required statements are inserted into the program at the point of allocation rather than in the prologue.
Since array bounds and string sizes of static data are required by the language to be constant, and since all values of the initial attribute of static data must be constant, the compiler is able to initialize the static data at compi1c time. The initialization is done by the code generator at the time it allocates the static data.
Semantic translation
The semantic translator transforms the internal representation so that it reflects the attributes (semantics) of the declared variables without reflecting the properties of the object machine. It makes a single scan over the internal representation of the program. A compiler, which had no equivalent of the optimizer phase and which did not separate the machine dependencies into a separate phase, could conceivably produce object code during this scan.
Organization of the semantic translator
The semantic translator consists of a set of recursive procedures which walk through the program tree. The actions taken by these procedures are described by the general terms: operator transformation and operand processing. Operator transformation includes the creation of an explicit representation of each operator's result and the generation of conversion operators for those operands which require conversion. Operand processing determines the attributes, size and offsets of each operator's operands.
Operator transformation
The meaning of an operator is determined by the attributes of its operands. This meaning specifies which conversions must be performed on the operands, and it decides the attributes of the operator's result.
An operator's result is represented in the program tree by a temporary node. Temporary nodes are a further qualification of the original operator. For example, an add operator whose result is fixed-point is a distinct operation from an add operator whose result is floating-point. There is no storage associated with temporaries--they are allocated either core or register storage by the code generator. A temporary's size is a function of the operator's meaning and the sizes of the operator's operands. A temporary, representing the intermediate result of a string operation, requires an expression to represent its length if any of the string operator's operands have variable lengths.
Operand processing
Operands consist of sub-expressions, references to variables, constants, and references to procedure names or built-in functions. Sub-expression operands are processed by recursive use of operator transformation and operand processing. Operand processing converts constants to a binary format which depends on the context in which the constant was used. References to variables or procedure names are associated with their appropriate declaration by the search function. After the search function has found the appropriate declaration, the reference may be further processed by the subscriptor or function processor.
The Search function
During the parse, it is not possible for references to source program variables to know the declared attributes of the variable because the PL/1 language allows declarations to follow their use. Therefore, references to source program variables are placed into a form which contains a pointer to a token table entry rather than to a declaration of the variable. Figure 3 shows the output of the parse. The search function finds the proper declaration for each reference to a source program variable. The effectiveness of the search depends heavily on the structure of the token table and the symbol table. After declaration p
TOP: PROC; DCL B POINTER; BEGIN; DCL B FLOAT; BEGIN; DCL B FIXED; END; END; END;Figure 4-The relation between token table and the symbol table The search function first tries to find a declaration belonging to the block in which the reference occurred. If it fails to find one, it looks for a declaration in the next containing block. This process is repeated until a declaration is found. Since the number of declarations on the list is usually one, the search is quite fast. In its attempt to find the appropriate declaration, the search function obeys the language rules regarding structure qualification. It also collects any subscripts used in the reference and places them into a subscript list. Depending on the attributes of the referenced item, the subscript list serves as input to the function processor or subscriptor.
The declaration processor creates offset expressions and size expressions for all variables. These expressions, known as accessing expressions, are rooted in a reference node which is attached to a symbol table node. The reference node contains all information necessary to access the data at run time. The search function translates a source reference into a pointer to this reference node. See Figure 5.
DEM: PROC; DCL 1 S, 2 A(N) FLOAT, 2 B(M) FIXED; S.B(I) = 0; END;Figure 5-A simplified diagram showing the effects of subscripting
Subscripting
Since each subscripted reference is unique, its offset expression is unique. To reflect this in the internal representation, the subscriptor creates a unique reference node for each subscripted reference. See Figure 6.
Figure 6-The internal representation of a statement before and after the execution of the search function. The broken lines show the statement's operands before the search The following discussion shows the relationship between the declared array bounds, the element size, the array offset and subscripts.
Let us consider the case of an array declared :
a(l1:ul, 12:u2, . . . ln:un )
Its element size is s and its offset is b. The multipliers for the array are defined as:
mn = s
mn-l = (un - ln + 1)s
mn-2 = (un-1 - ln-1 + 1)mn-1
.
.
.
m1 = (u2 - l2 + 1)m2
The offset of a reference a(i1, i2, ... , in) is computed as:
v + Σ ijmj
where: v is the virtual origin. The virtual origin is the offset obtained by setting the subscripts equal to zero. It serves as a convenient base from which to compute the offset of any array elements. During the construction of all expressions, the constant terms are separated from the variable terms and all constant operations are performed by the compiler. Since the virtual origin and the multipliers are common to all references, they are constructed by the declaration processor and are repeatedly used by the subscriptor.
Arrays of PL/1 structures which contain arrays may result in a set of multipliers whose units differ. The declaration:
DCL 1 S(10), 2 A PTR, 2 B(10) BIT(2);yields two multipliers of different units. The first multiplier is the size of an element of S in words, while the second multiplier is the size of an element of B in bits.Array parameters which may correspond to an array cross section argument must receive their multipliers from an argument descriptor. Since the arrangement of the cross section elements in storage is not known to the called program, it cannot construct its own multipliers and must use multipliers prepared by the calling program. Note that the current definition of PL/1 allows any array parameter to receive a cross section argument.
The function processor
An operand which is a reference to a procedure is expanded by the function processor into a call operator and possible conversion operators. Built-in function references result in new operators or are translated. into expressions consisting of operators and operands.
Generic procedure references
A generic entry name represents a family of procedures whose members require different types of arguments.DCL ALPHA GENERIC ( BETA ENTRY (FIXED)), GAMMA ENTRY(FLOAT)) );A reference to ALPHA (X) will result in a call to BETA or GAMMA depending on the attributes of X.The declaration processor chains together all members of a generic family and the function processor selects the appropriate member of the family by matching the arguments used in the reference with the declared argument requirements of each member. When the appropriate member is found, the original reference is replaced by a reference to the selected. member.
Argument processing
The function processor matches arguments to user-declared procedures against the argument types required for the procedure. It inserts conversion operators into the program tree where appropriate, and it issues diagnostics when it detects illegal cases.The return value of a function is processed as if it were the n + lth argument to the procedure, eliminating the distinction between subroutines and functions.
The function processor determines which arguments may possibly correspond to a parameter whose size or array bounds are not specified in the called procedure. In this case, the argument list is augmented to include the missing size information. A more detailed description of this issue is given later in the discussion of object code strategies.
The built-in function processor
The built-in function processor is basically a table driven device. The driving table describes the number and kind of arguments required by each function and is used to force the necessary conversions and diagnostics for each argument. Most functions require processing which is unique to that function, but the table driven device minimizes the amount or this processing.The SUBSTR built-in function is of particular importance since it is a basic PL/1 string operator. It is a three argument function which allows a reference to be made to a portion of a string variable, i.e., SUBSTR (X, I, J) is a reference to the ith through i + j -1th character (or bit) in the string x.
This function is similar to an array element reference in the sense that they both determine the offsets of the reference. The processing or the SUBSTR function involves adjusting the offset and length expressions contained in the reference node of X. As is the case in all compiler operations on the offset expressions, the constant and variable terms are separated to minimize the object code necessary to access the data.
The optimizer
The compiler is designed to produce relatively fast object code without the aid of an optimizing phase. Normal execution of the compiler will by-pass the optimizer, but if extensively optimized object code is desired, the user may set a compiler command option which will execute the optimizer. The optimizer consists of a set of procedures which perform two major optimizations: common sub-expression removal and removal of computations from loops. The data bases necessary for these optimizations are constructed by the parse and the semantic translator. These data bases consist of a cross-reference structure of statement labels and a tree structure representing the DO groups of each block. Both optimizations are done on a block basis using these two data bases.
Although the optimizer phase was not implemented at the time this paper was written, all data bases required by the optimizer are constructed by previous phases of the compiler and the abnormality of all variables is properly determined.
Optimization of PL/I programs
The on-condition mechanism of the PL/1 language makes the optimization of PL/1 programs considerably more difficult than the optimization of Fortran programs. Assuming that an optimized version of a program should yield results identical to those produced by the un-optimized version, then if any on-conditions are enabled in a given region of the program, the compiler cannot remove or reorder the computations performed in that region. (Consider the case of a divide by zero on unit which counts the number of times that the condition occurs.)Since some on-conditions are enabled by default, most PL/1 programs cannot be optimized. Because of the difficulty of determining the abnormality of a program's variables, the optimization of those programs which may be optimized requires a rather intelligent compiler. A variable is abnormal in some block if its value can be altered without an explicit indication of that fact present in that block. An optimizing PL/1 compiler must consider all based variables, all arguments to the ADDR function, all defined variables, and all base items of defined variables to be abnormal, If the compiler expects values of variables to be retained throughout the execution of a call, it must also consider all parameters, all external variables, and all arguments of irreducible functions to be abnormal.
Because of the difficulty of optimizing programs written in the current PL/1 language [1] compilers should probably not attempt to perform general optimizations but should concentrate on special case optimizations which are unique to each implementation. Future revisions to the language definition may help solve the optimization problem.
The code generator
The code generator is the machine dependent portion of the compiler. It performs two major functions: it allocates data into Multics segments and it generates 645 machine instructions from the internal representation.
Storage allocation
A module of the code generator called the storage allocator scans the symbol table allocating stack storage for constant size automatic data, and linkage segment storage for internal static data. For each external name the storage allocator creates a link (an out-reference) or a definition (an entry point) in the linkage segment. All internal static data is initialized as its storage is allocated.
Due to the dynamic linking and loading characteristics of the Multics environment, the allocation and initialization of external static storage is rather unusual. The compiler creates a special type of link which causes the linker module of the operating system to create and initialize the external data upon first reference. Therefore, if two programs contain references to the same item of external data, the first one to reference that data will allocate and initialize it.
Code generation
The code generator scans the internal representation transforming it into 645 machine instructions which it outputs into the text segment. During this scan the code generator allocates storage for temporaries, and maintains a history of the contents of index registers to prevent excessive loading and storing of index values.
Code generation consists of three distinct activities: address computation, operator selection and macro expansion. Address computation is the process of transforming the offset expressions of a reference node into a machine address or an instruction sequence which leads to a machine address. Operator selection is the translation of operators into n-operand macros which reflect the properties of the 645 machine.
A one-to-one relationship often exists between the macros and 645 instructions but many operations (load long string, etc.) have no machine counterpart. All macros are expanded in actual 645 code by the macro expander which uses a code pattern table (macro skeletons) to select the specific instruction sequences for each macro.
Object code strategies
The object code design
The design of the object code is a compromise between the speed obtainable by straight in-line code and the necessity to minimize the number of page faults caused by large object programs.The length of the object program is minimized by the extensive use of out-of-line code sequences. These out-of-line code sequences represent invariant code which is common to all Multics PL/1 object programs. Although the compiled code makes heavy use of out-of-line code sequences, the compiled code is not in any respect interpretive. The object code produce for each operator is very highly tailored to the specific attributes of that operator.
All out-of-line sequences are contained in a single "operator" segment which is shared by all users. The in-line code reaches on out-of-line sequence through transfer instructions, rather than through the standard subroutine mechanism. We believe that the time overhead associated with the transfers is more than redeemed by the reduction in the number of page faults caused by shorter object programs. System performance is improved by insuring that the pages of the operator segment are always retained in storage.
The stack
Multics PL/1 object programs utilize a stack segment for the allocation of all automatic data, temporaries, and data associated with on-conditions. Each task (Multics process) has its own stack which is extended (pushed) upon entry to block and is reverted (popped) upon return from a block. Prior to the execution of each statement it is extended to create sufficient space for any variable length string temporaries used in that statement. Constant size temporaries are allocated at compile time and do not cause the stack to be extended for each statement.
Prologue and epilogue
The term prologue describes the computations which are performed after block entry and prior to the execution of the first source statement. These actions include the establishment of the condition prefix, the computation of the size of variable size automatic data, extension of the stack to allocate automatic data, and the initialization of automatic data. Epilogues are not needed because all actions which must be undone upon exit from the block are accomplished by popping the stack. The stack is popped for each return or non-local go to statement.
Accessing of data
Multics PL/1 object code addresses all data, including members of variable sied structures and arrays directly through the use of in-line code. If the address of the data is constant, it is computed at compile time. If it is a mixture of constant and variable terms, the constant terms are combined at compile time. Descriptors are never used to address or allocate data.
String operations
All string operations are done by in-line code or by "transfer" type subroutinized code. No descriptors or calls are produced for string operations. The SUBSTR built-in function is implemented as apart of the normal addressing code and is therefore as efficient as a subscripted array reference.
String temporaries
A string temporary or dummy is designed in such a way that it appears to be both a varying and non-varying string. This means that the programmer does not need to be concerned with whether a string expression is varying or non-varying when he uses such an expression as an argument.
Varying Strings
The Multics PL/1 implementation of varying strings uses a data format which consists of an integer followed by a non-vayring string whose length is the declared maximum of the varying string. The integer is used to hold the current size of the string in bits or characters. Using this data format, operations on vayring strings are just as efficient as operations on non-vayring strings.
On-conditions
The design of the condition machinery minimizes the overhead associated with enabling and reverting on-units and transfers most of the cost to the signal statement. All data associated with on-conditions, including the condition prefix, is allocated in the stack. The normal popping of the stack reverts all enabled on-units and restores the proper condition prefix. Stack storage associated with each block is threaded backward to the previous block. The signal statement uses this thread to search back through the stack looking for the first enabled unit for the condition being signaled. Figure 7 shows the organization of enabled on-units in the stack.
Procedure A enabled an on-unit for condition X and called procedure B.
Procedure B enabled an new on-unit for condition X and an on-unit for condition Y. It then called procedure C.
Procedure C did not enable any on-units.Figure 7-Stack storage and the signal mechanism
A signal for condition X causes the signal mechanism to search back through the stack until it finds the first enabled on-unit for condition X.
An on-unit is compiled as an internal procedure. The execution of an ON-statement creates a block of on-unit control data. This control data consists of the name of the condition for which the unit was enabled and a procedure variable. The signal mechanism uses the procedure variable to invoke the on-unit. All data associated with the enabled on-unit is stored in the stack storage of the procedure which enabled it. Normal popping of the stack reverts the on-units enabled during the execution of the procedure.Argument passing
The PL/1 language permits parameters to be declared with unknown array bounds or string lengths. In these cases, the missing size information is assumed to be supplied by the argument which corresponds to the parameter. This missing size information is not explicitly supplied by the programmer as is the case in Fortran, rather it must be supplied by the compiler as indicated in the following example:
SUB: PROC(A); . . . DCL A CHAR(*); . . .MAIN: PROC ; . . . DCL SUB ENTRY; DCL B CHAR(l0); CALL SUB(B) ; . . .Since parameter A assumes the length of the argument B, the compiler must include the length of B in the argument list of the call to SUB.
The declaration of an entry name may or may not include a description of the arguments required by that entry. If such a description is not supplied, then the calling program must assume that argument descriptors are needed, and must include them in all cans to the entry. If a complete argument description is contained in the calling program, the compiler can determine if descriptors are needed for calls to the entry.
In the previous example the entry SUB was not fully declared and the compiler was forced to assume that an argument descriptor for B was required. If the entry had been declared SUB ENTRY (CHAR(*)) the compiler could have known that the descriptor of B was actually required by the procedure SUB. Since descriptors are often created by the calling procedure but not used by the called procedure, it is desirable to separate them from the argument information which is always used by the called procedure.
Communication between procedures written in PL/1 and other languages is facilitated if the other languages do not need to concern themselves with PL/1 argument descriptors. The Multics PL/1 implementation of the argument list is shown in Figure 8. Note that the argument pointers point directly to the data (facilitating communication between languages) and that the descriptors are optional, also note that PL/1 pointers must be capable of bit addressing in order to implement unaligned strings. Since descriptors contain no addressing information, they are quite often constant and can be prepared at compile time.
Figure 8-An argument list showing the relationship between arguments and their descriptors. The broken lines indicate that descriptors are optional. SUMMARY
Our experiences both as users and implementors of PL/1 have led us to form a number of opinions and insights which may be of general interest.
- It is feasible, but difficult, to produce efficient object code for the PL/1 language as it is currently defined. Unless a considerable amount of work is invested in a PL/1 compiler, the object code it generates will generally be much worse than that produced by most Fortran or COBOL compilers.
- The difficulty of building a compiler for the current language has been seriously underestimated by most implementors. Unless the language is markedly improved and simplified this problem will continue to restrict the availability and acceptance of the language and will lead to the implementation of incompatible dialects and subsets. [7]
- Simplification of the existing language will make it more suitable to users and implementors. We believe that the language can be simplified and still retain its "universal" character and capabilities.
- The experience of writing the compiler in PL/1 convinced us that a subset of the language is well suited to system programming. This conviction is supported by Professor Corbató in his report on the use of PL/1 as an implementation language for the Multics system. [8] Many PL/1 concepts and constructs are valuable, but PL/1 structures and list processing seem to be the principal improvement over alternative languages. [9]
ACKNOWLEDGMENTS
The author wishes to express recognition to members of the General Electric Multics PL/1 Project for their contributions to the design and implementation of the compiler. J. D. Mills was responsible for the design and implementation of the syntactic analyzer and the Multics system interface, B. L. Wolman designed and built the code generator and operator segment, and G. D. Chang implemented the semantic translator. Valuable advice and ideas were provided by A. H. Kvilekval. The earlier work of M. D. McIlroy and R. Morris of Bell Telephone Laboratories and numerous persons at MIT's Project MAC provided a useful guide and foundation for our efforts.
REFERENCES
- PL1 Language specifications Form Y33-6003-0 IBM Corp March 1968
- The formal definition of PL/1 as specified by technical reports TR25.081, TR25.082, TR25.083, TR25.0S4, TR25.085, TR25.086 and TR25.087, IBM Corp Vienna Austria June 1968
- F J CORBATÓ V A VYSSOTSKY Introduction and overview of the Multics System Proc FJCC 1965
- V A VYSSOTSKY F J CORBATÓ R M GRAHAM Structure of the Multics supervisor Proc FJCC 1965
- R C DALEY J B DENNIS Virtual memory, processes. and sharing in Multics CACM Vol 11 No 5 May 1968
- PL/1 (F) programmer's guide Form C2S-6594-3 IBM Corp Oct 1967
- R F ROSIN PL/1 Implementation survey ACM SIGPLAN Notices Feb 1969
- F J CORBATÓ PL/1 as a tool for system programming Datamation May 1969
- H W LAWSON JR PL/1 List processing CACM Vol 10 No 6 June 1967
1969 Fall Joint Computer Conference
"This material is presented to ensure dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder."
Jeff Barr's Blog
...I learned Fortran IV in my first semester. Around the same time I started my first programming job, at a small Bethesda company called Moshman Associates. My first task there was to write a macro assembler for the 6502 microprocessor. I wrote a Fortran simulation of the hashing algorithm that we had planned to use for instructions and labels, found that it had an excessively high number of collisions, and was given a nice raise for my trouble.
In my second semester I took a class in PL/I programming. Designed by IBM, PL/I was a clean, structured, and relatively complex language. The compiler had many, many options for optimization and for diagnostic output. I spent a lot of time experimenting with the options and carefully inspecting the resulting printouts in an attempt to write the most efficient code possible.
I need to explain how we would write and run our code at that time. We didn't have our own PCs and we didn't have terminals to log in to a time-sharing system. Instead, we would use an IBM 029 card punch to punch each line of code into a punched card. The 029 was a complex mechanical device, with noises, rhythms, and so forth. The cards were assembled into a deck, preceded by some job control language (JCL) statements which provided a name for the job and instructed the computer how to set up input and out devices and how to compile and run the code. Small decks could be rubber-banded together for safekeeping; larger decks (usually for COBOL programs) were best kept in the cardboard boxes that originally held the blank, unpunched cards.
Once the deck was ready, I would walk up the hall to the job submission window, hand it in to the woman behind the counter, and she would stack it up in the card reader for eventual processing. At crunch times there would be line of students and a big pile of unprocessed jobs.
When it was my deck's turn to be run, she would load it into the card reader, the computer would read and process the cards, and print the results on a very fast IBM printer. The attendant would take the printout, wrap it around the cards, and file it away until I came back to the window to collect the results.
On a good day the turnaround time would be about 3 to 4 hours. At crunch time it might take slightly longer. If all went well the printout would include two sections - the evidence of a successful compilation, and the results of actually running the program. I quickly learned to be careful with my code and with my algorithms, so that my code would compile and run after just a few iterations. Others were not so fortunate, and would spend many hours waiting for their results, only to find that they'd misplaced some punctuation, forgotten to declare a variable, or made an algorithmic mistake. I remember one of my fellow students "bragging" that "I am getting pretty good at this, it only took me 30 tries to get it to compile."
I remember taking away a couple of things from these early experiences. First, there was great value in desk checking your code and your algorithms to increase the odds of a successful run. Second, it was good to have several projects going simultaneously to make the best of your your time. Third, I was always shocked (from reading my printouts) to see that my code could wait in the queue for several hours in order to be compiled and run in the space of 2 or 3 seconds.
As I mentioned earlier, the IBM line printer had a unique feature known as carriage control. By punching different special characters in the first column you could make the printer do some special things when it printed out your code. For example a "1″ would make it advance to the top of the next page of green bar paper before it would print. This was a good way to make sure that each function was on a page of its own. The "+" (plus) sign was magic; it would inhibit the printer from advancing the paper to the next line after printing. The next line would overstrike the current line.
I learned how to put it to very good use at the end of my PL/I class. The instructor asked us to make our final assignment look as pretty as possible. For most people this meant clean comments, good variable names, a clean structure, and so forth.
I decided to go a step further! Because this was a school, they would do their best to get as much use of each printer ribbon as possible. Instead of printing in a solid black color, the printer would usually produce text that was, at best, a medium gray. I did some experimenting, and found that 3 overstrikes would create nice, black text.
I decided to see if I could use the overprinting feature to make my final PL/I program look really nice. After getting my code to work as desired, I set out to use bold highlighting on all of the variable names. This turned out to be easy, although I spent a lot of time on the card punch. Here's what I did.
First, before going any further, I should explain that PL/I used the characters /* to open a comment and */ to close one. The comments were free-form, and could flow from one card to the next as desired.
Let's say that I was writing a simple loop. The actual, unadorned PL/I code and comment would look like this:
To make the MONTH variable bold I punched a series of cards like this:
The compiler saw a DO statement with a very long comment. The DO statement would look like this on the printout:
DO MONTH = 1 TO 12; /* PROCESS EACH MONTH */ The use of this irregular carriage control upset the otherwise rhythmic sounds made by the printer and the operators sometimes thought that the printer had jammed and would cancel the job. Once they realized that it was me (one benefit of going to a small school) they allowed it to run to completion.
Needless to say, I aced the class!
My PL/I knowledge turned out to be quite useful. Within a year I worked on a project for the National Science Foundation. I wrote a very cool program that would verify the accuracy of grant data, basically adding up the rows and columns to make sure that they matched in the application (an inverse spreadsheet). A year or two later I used Digital Research's very capable PL/I-80 compiler to prototype some of my own ideas for a spreadsheet.
Note: I used Ralf Kloth's Punchcard emulator to create the card images.
Introduction
This document provides information on using the Iron Spring PL/I compiler and compiled programs on the Linux platform. For information on the OS/2 platform, see the corresponding document readme_os2.
Jul 25, 2012 | YouTube
Download the free PL/1 compiler from Iron Spring as a zipped tar file - unpack it using gzip -d and tar xvf within your own PL1 sub folder (directory). within the pli-0.9.1 sub folder, run make install as superuser, then make your own code sub directory. Copy the Makefile from samples, edit this file to call the name of your own pl/1 program. Run make to compile it (still within your own code sub - dir ). Thanks for watching
Mombu the Programming Forum
The Liant product was licensed from us originally as the ANSI subset G implementation, and they extended it quite a bit. It is a good compiler at least when I last tried it under HP-UX ca. 1993, I was able to compile our PL/I compiler with it. Their debugger, Codewatch, wasn't bad. Don't know what they have done with it in the intervening years.
Tom
Jan 02, 2008
Hanz Schmidt :
What is ther status os PLI-GCC??
Henrik
It currently parses most of the PL/I language, but no code generation is done. Currently I have little time to work on the pl1gcc project. Given the interest in a free working PL/I compiler, I am inviting more developers, docu-writers and testers to join the effort. The more the merrier. It is a huge task to create a compiler, let alone when there is only one active developer (me).
Henrik Sorensen
The recent availability of a rather larger body of Multics code is doubtless a useful thing from a testing point of view...
This is the fifteenth code drop of the GCC front-end for the PL/I programming language.
PL/I for GCC is released under the terms of the GNU Public License; version 2.With pl1gcc-0.0.15 the preprocessor do loop, %DO, has been partly implemented. Only one level is allowed.
This required quite a bit of restructuring of the internal code. But now it is easy to add more preprocessor statements like %IF and preprocessor %PROCEDUREs. Expect some more releases soon.
Further the internal parse tree has also been improved, so code generation should begin really soon now (tm).There is still no code generation taking place, so don't run out and uninstall your production PL/I compiler just yet :-)
Changes in v0.0.15:
- restructuring parser stack
- improve internal interface to preprocessor
- improved error messages with declares
- synchronize with gcc version 4.3 (20070810)
Dialect type 1: PL/C Cornell University PL/I
Dialect type 2: PL/I for IBM series 1
Dialect type 3: PL/I-D IBM PL/I subset compiler that runs under DOS
Dialect type 4: PL/I-F IBM PL/I full language compiler runs under DOS
Dialect type 5: DRI PL/I-D DIGITAL RESEARCH PL/I general purpose subset
Dialect type 6: IBM optimizer PL/I compiler runs under DOS
Dialect type 7: IBM optimizer PL/I - OS
Dialect type 8: ANSI X3.7-1987 PL/I general purpose subset
Dialect type 9: ANSI x3.53-1976, ISO 6160-1979 PL/I
Dialect type A: Prime PL/I
Dialect type B: Stratus PL/I
Dialect type C: Data General PL/I
Dialect type D: VAX PL/IORDER: PL1C type x ( select one from above)
The PL1C® translators contain a syntax analyzer, a PL/I to tertiary converter, and a tertiary to C converter. The syntax analyzer scans the PL/I input file for syntactic errors and generates a listing file of the PL/I program. Any syntactic errors will be flagged with detailed English messages in the listing file. If no errors are encountered, then the PL/I input file is converted to tertiary language.
The transfer of the PL/I source language into an intermediate tertiary language ensures the logical equivalence between the source and target languages. This tertiary language is common to the entire family of our translators. The tertiary language is automatically converted to C while maintaining the logical equivalence between the output C program and the input PL/I program.
July 22, 2010 | IBM
IBM Enterprise PL/I is a leading-edge, z/OS-based compiler that helps you create and maintain mission-critical, line-of-business PL/I applications to execute on your z/OS systems. It gives you access to IBM DB2®, IBM CICS®, and IBM IMSTM systems, and other data and transaction systems. This compiler facilitates your new On Demand Business endeavors by helping to integrate PL/I and Web-based business processes in Web services, XML, Java, and PL/I applications. This compiler's interoperability helps you capitalize on existing IT investment while more smoothly incorporating new, Web-based applications as part of your organization's infrastructure. Version 4 offers exploitation for the latest hardware architecture contained in the new zEnterprise 196, compiler enhancements for improved debugging using Debug Tool, and a number of usability enhancements, as well as additional quality improvements, many of them customer-requested. This new version of Enterprise PL/I for z/OS V4.1 underscores the continuing IBM commitment to the PL/I programming language on the z/OS platform. With Enterprise PL/I for z/OS V4.1, you can leverage more than 30 years of IBM experience in application development.
Multics
University courses
Etc
IBM Red Books
Rich, Robert P. Internal Sorting Methods Illustrated with PL/I Programs. Englewood Cliffs: Prentice-Hall, 1972.
Sebesta, Robert W. Concepts of Programming Languages. 3rd ed. Menlo Park: Addison-Wesley, 1996.
Abel, Peter Structured programming in PL/I and PL/C: a problem-solving approach Reston, VA, Reston Publishing Co., 1985; 571p. ISBN: 0-83597122-8
Abrahams, Paul The PL/I Programming Language New York, NY, The Courant Instutute of Mathematical Sciences, New York University, 1979; 151p.
Alber, K., Oliva, P., and Urschler, H. The Concrete Syntax of PL/I Vienna, At, IBM Laboratory, 1968
Technical Report TR 25.084
Alber, K., and Oliva, P. Translation of PL/I into Abstract Text Vienna, At, IBM Laboratory, 1968
Technical Report TR 25.086
Allen, C.D., et. al. An abstract interpreter of PL/I IBM United Kingdom Labs, 1966 Technical Note TN3004
American National Standards Institute
American National Standard: programming language PL/I
New York, NY, American National Standards Institute, 1979 (Rev 1998); 403p.
ANSI Standard X3.53-1976
American National Standards Institute
American National Standard: information systems - programming language - PL/I general-purpose subset New York, NY, American
National Standards Institute, 1987; 449p.
ANSI Standard X3.74-1987
American National Standards Institute
Information Processing Systems Technical Report Real-Time Extensions for PL/I (NOT AN AMERICAN NATIONAL STANDARD)
New York, NY, American National Standards Institute, 1989.
ANSI Standard ANSI X3/TR-7-1989
Anderson, Mary Ellen
PL/I for Business Applications
Englewood Cliffs, NJ, Prentice-Hall, 1973; 397p.
ISBN: 0-136-76957-8
Anklam, Patricia, et. al.
Engineering a Compiler; VAX-11 Code Generation and Optimization
Bedford, MA, Digital Press, 1982; 269p.
ISBN: 0-932-37619-3
Augenstein, Moshe and Tenenbaum, Aaron
Data Structures and PL/I Programming
Englewood Cliffs, NJ, Prentice-Hall, 1979; 643p.
ISBN: 0-131-97731-8
Barnes, Robert Arthur
PL/I for programmers
New York, NY, North Holland, 1979; 561p.
ISBN: 0-444-00284-7
Bates, Frank, and Douglas, Mary L.
Programming Language/One, 2nd ed.
Englewood Cliffs, NJ, Prentice-Hall, 1970; 420p.
Beech, D. et. al.
Abstract Syntax of PL/I
IBM United Kingdom Labs, 1966
Technical Note TN3002
Beech, D. et. al.
Concrete Syntax of PL/I
IBM United Kingdom Labs, 1966
Technical Note TN3001
Beech, D. Nicholls, J.E., and Rowe, R.
A PL/I translator
IBM United Kingdom Labs, 1966
Technical Note TN3003
Brown, Gary DeWard
Fortran to PL1 Dictionary PL/1 to Fortran Dictionary
New York, NY, John Wiley and Sons, 1975
ISBN: 0-471-10796-4
Clark, Frank James
Introduction to PL/1 Programming
Boston, MA, Allyn and Bacon, 1971; 244p.
Conway, Richard
Programming for Poets: A Gentle Introduction Using PL/1
Cambridge, MA, Winthrop Publishers, 1978; 347p.
ISBN: 0-876-26724-X
Conway, Richard, and Gries, David
An Introduction to Programming.
A Structured Approach Using PL/I and PL/C
Cambridge, MA, Winthrop Publishers, Inc., 1973; 460p.
ISBN: 0-876-26406-2
Dadashzadeh, M.
PL/1 Programming Language Essentials
Piscataway, NJ, Research and Education Association, 1990; 112p.
ISBN: 0-878-91695-4
Davis, Charles Hargis
Illustrative Computer Programming for Libraries
Westport, CT, Greenwood Press, 1981; 129p.
ISBN: 0-313-22151-0
Davis, Kathi H., and Domina, Lyle
Structured Programming: PL/I with PL/C
New York, NY, Holt, Rinehart and Winston, 1988; 683p.
ISBN: 0-030-03723-9
Edwards, Leonard E.
PL/I for Business Applications
Reston, VA, Reston Pub. Co., 1973; 480p.
ISBN: 0-879-09631-4, 0-879-09630-6
Fike, C[harles]. T.
PL/I for scientific programmers
Englewood Cliffs, NJ, Prentice-Hall, 1970; 241p.
Fosdick, Howard
Structured PL/I Programming: for textual and library processing
Littleton, CO: Libraries Unlimited, 1982; 304p.
ISBN: 0-872-87328-5
Groner, Gabriel F.
PL/I programming in technological applications
New York, NY, Wiley-Interscience, 1971; 230p.
ISBN: 0-471-32795-6
Harrow, Keith, Goldberg, David E., and Langsam, Yedidyah
Problem Solving Using PL/I and PL/C
Englewood Cliffs, NJ, Prentice-Hall, 1984
Hughes, Joan Kirkby
PL/I Structured Programming, 3rd Ed.
New York, NY, John Wiley & Sons, 1987; 656p.
Hughes, Joan K., and La Pearl, Barbara J.
Structured Programming Using PL/C
New York, NY, John Wiley & Sons, 1981; 414p.
ISBN: 0-471-04969-7
IBM Corporation
A Guide to PL/I for Commercial Programmers
White Plains, NY, International Business Machines Corp.
IBM Publication number C20-1651
IBM Corporation
A Guide to PL/I for FORTRAN Users
White Plains, NY, International Business Machines Corp., 1967; 36p.
IBM Publication number C20-1637
IBM Corporation
An Introduction to Structured Programming in PL/I
White Plains, NY, International Business Machines Corp., 1967; 51p.
IBM Publication number SC20-1777-1
IBM Corporation
An Introduction to the List Processing Facilities of PL/I
White Plains, NY, International Business Machines Corp., 1971; 87p.
IBM Publication number GF20-0015-1
IBM Corporation
Student Language - A Teaching Subset of PL/I - Teaching Guide
White Plains, NY, International Business Machines Corp.
IBM Publication number GR09-0004-1
IBM Corporation
Student Text; A PL/I Primer
White Plains, NY, International Business Machines Corp., 1977; 72p.
IBM Publication number C28-6808-0
Kennedy, Michael, and Solomon, Martin B.
Structured PL/zero plus PL/one
Englewood Cliffs, NY, Prentice-Hall, 1977; 695p.
ISBN: 0-138-54901-X
Lamie, Edward L.
PL/I Programming: A Structured, Disciplined Approach
Belmont, CA, Wadsworth Publishing Co., 1982; 330p.
ISBN: 0-534-01067-9
Lecht, Charles Philip
The Programmer's PL/I; a Complete Reference.
Forward by Robert Bemer
New York, NY, McGraw-Hill, 1968; 427p.
Lewi, Johan, and Pardaens, Jan
Data Structures of Pascal, Algol 68, PL/I, and Ada
New York, Springer-Verlag, 1986; 395p.
Logicon, inc.
Guide to PL/I / prepared under contract F19628-67-C-0396 by Logicon Incorporated
Detroit, MI, American Data Processing, inc., 1969; 2v.
Lucas, P., et. al.
Informal Introduction to the abstract syntax and interpretation of PL/I
Vienna, At, IBM Laboratory, 1968
Technical Report TR 25.083
Mott, Thomas H., Artandi, Susan, and Struminger, Leny
Introduction to PL/1 Programming for Library and Information Science
New York, NY, Academic Press, 1972; 231p.
Pollack, S.V., and Sterling, T.D.
A Guide to PL/I
New York, NY, Holt, Rinehart and Winston, Inc.,1969; 556p.
Pritsker, A. Alan B., and Young, Robert E.
Simulation with GASP-PL/I: a PL/I based continuous/discrete simulation language
New York, NY, Wiley, 1975; 351p.
ISBN: 0-471-70046-0, 0-608-11634-3
Reddy, Rama N. and Ziegler, Carol A.
PL/I: Structured Programming and Problem Solving
Saint Paul, MN, West Publishing Company, 1986; 739p.
ISBN: 0-314-93915-6
Rich, Robert P.
Internal sorting methods illustrated with PL/1 programs
Englewood Cliffs, NJ., Prentice-Hall, 1972; 154p.
ISBN: 0-134-72357-0
SHARE Inc.
The PL/I programming project techniques library
Chicago, IL, SHARE, Inc., 1975; 129p.
Shelly, Gary B., and Cashman, Thomas J.
Introduction to Computer Programming IBM System/360 PL/I
Fullerton, CA, Anaheim Publishers, 1978
ISBN: 0-882-36190-2
Shortt, Joseph, and Wilson, Thomas C.
Problem solving and the Computer: A structured Concept with PL/I (PL/C)
Reading, MA, Addison-Wesley, 1976; 372p.
ISBN: 0-201-06916-4
Sprowls, R. Clay
PL/C: a processor for PL/I
San Francisco, CA, Canfield Press, 1972; 247p.
ISBN: 0-063-88591-3
Sterling, Theodor D. and Pollack, Seymour V.
Computing & Computer Science; A First Course with PL/I
New York, NY, Macmillan Co., 1970; 414p.
Stoutemyer, David R.
PL/I Programming for Engineering and Science
Englewood Cliffs, NJ, Prentice-Hall, 1971; 363p.
ISBN: 0-136-76528-9
Tremblay, Jean-Paul, and Sorenson, Paul G.
An Implementation Guide to Compiler Writing
New York, NY, McGraw-Hill, 1982
ISBN: 0-070-65166-3
Vowels, Robin A.
Introduction to PL/I, Algorithms and Structured Programming, 3rd Ed.
Parkville, Vic. AU, Robin Vowels, 1998
ISBN: 0-959-63849-0 [includes disc]
Walk, K., et. al.
Abstract syntax for interpretation of PL/I
Vienna, At, IBM Laboratory, 1968
Technical Report TR 25.082
Weinberg, Gerald M.
PL/I Programming: A Manual of Style
New York, NY, McGraw-Hill, 1970; 441p.
Weinberg, Gerald M.
PL/I Programming Primer
New York, NY, McGraw-Hill, 1966; 278p.
Weinberg, Gerald M., Yasukawa, Norie, and Marcus, Robert
Structured Programming in PL/C; an Abecedarian
New York, NY, John R. Wiley and Sons, 1973; 220p.
Weiss, Eric A.
The PL/1 Converter
New York, NY, McGraw-Hill, 1966; 113p.
Yalow, Edward C.
YAQ: A 360 Assembler Version of the Algorithm A and Comparison with other PL/I Programs
Urbana-Champaign, IL, University of Illinois at Urbana-Champaign, 1977; 31p.
Abrahams, Paul W.
"The CIMS PL/I Compiler"
Proceedings of the SIGPLAN Symposium on Compiler Construction
Denver, CO; Aug 6-10, 1979; 107-116.
Abrahams, Paul
"The PL/I Standard: An Apostate's View"
ACM SIGPLAN Notices, Sep 1979; 15-16.
Abrahams, Paul W.
"Subset/G PL/I and the PL/I Standard"
Proceedings of the 1983 Annual Conference on Computers: Extending the Human Resource, 1983; 130-132.
Adams, J. Mack, Inmon, William H., and Shirley, Jim.
"PL/I in the computer science curriculum"
Papers of the second ACM SIGCSE symposium on Education in computer science, 1972; 116-126.
Barnes, Richard
"A Working Definition of the Proposed Extensions for PL/I Real-Time Applications"
ACM SIGPLAN Notices, Oct 1979; 77-99.
Battarel, G.J., and Chevance, R.J.
"Requirements for a Safe PL/1 Implementation"
ACM SIGPLAN Notices, May 1978; 12-22.
Beech, D.
"A structural view of PL/I"
Computing Surveys 2(1970); 33-64.
Beech, David, and Marcotty, Michael
"Unfurling the PL/I Standard"
ACM SIGPLAN Notices, Oct 1973; 12-43.
Boulton, P.I.P., and Jeanes, D.L.
"The Structure and Performance of PLUTO, a Teaching Oriented PL/I Compiler System"
INFOR, Jun 1972; 140-153.
Burkhardt, Walter H.
"PL/I: An Evaluation"
Datamation, Nov 1966; 31-39.
Busam, Vincent A.
"A dictionary structure for a PL/I compiler"
International Journal of Parallel Programming 1.3 (1972): 235-253.
Chroust, Gerhard
"History of PL/I"
ICNL, 9(1978); p.148.
Conrow, Kenneth, and Smith, Ronald G.
"NEATER2: a PL/I source statement reformatter"
CACM 13(1970); 669-675.
Conway, Richard W., and Wilcox, Thomas R.
"Design and implementation of a diagnostic compiler for PL/I"
CACM 16(1973); 169-179.
Corbató, F. J.
"PL/I as a Tool for System Programming"
Datamation, 6 May 1969; 68-76.
Elshoff, James L.
"A Numerical Profile of Commercial PL/I Programs"
Software-Practice and Experience 6(1976): 505-525.
Elshoff, James L.
"The Influence of Structured Programming on PL/I Program Profiles"
IEEE Transactions on Software Engineering 3(1977): 364-368.
Elshoff, James L.
"A Study of the Structural Composition of PL/I Programs"
ACM SIGPLAN Notices, Jun 1978; 29-37.
Elson,M., and Rake, S.T.
"Code-generation technique for large-language compilers"
IBM Systems Journal 9(1970):166-188.
Epley, Donald, and Sjoerdsma, Ted.
"A two-semester course sequence in introductory programming using PL/1 - a rationale and overview"
The papers of the ACM SIGCSE ninth technical symposium on Computer science education, 1978; 113-119.
Frantz, Donald G.
"A PL/1 program to assist the comparative linguist"
CACM 13(1970); 353-356.
Freiburghouse, R.A.
"The Multics PL/I Compiler"
AFIPS Conference Proceedings: 1969 Fall Joint Computer Conference, Nov 1969; 187-199.
Gauthier, Richard L.
"PL/I compile time facilities"
Datamation, Dec 1968; 32-34.
Hac, Anna
"PL/I as a Discrete Event Simulation Tool"
Software - Practice and Experience 14(1984):697-702.
Harrow, Keith, Langsam, Yedidyah, and Goldberg, David E.
"Teaching PL/I Using a Microcomputer"
ACM SIGCSE Bulletin Sep 1986:19-25.
Hopkins, Mark
"SABRE/PLI"
Datamation, Dec 1968; 35-38.
Hopkins, Martin
"Problems of PL/I for System Programming"
Proceedings of the SIGPLAN symposium on Languages for System Implementation, Oct 1971; 89-91.
Irwin, Larry
"Implementing phrase-structure productions in PL/I"
CACM 10(1967); 424.
Jalics, Paul J.
"Cobol vs. PL/1: some performance comparisons"
CACM 27(1984); 216-221.
Lawson, Harold W.
"PL/I list processing"
CACM 10(1967); 358-367.
Lucas, P., and Walk, K.
"On the formal description of PL/I"
Annual Review of Automatic Programming 6(1969): 105-182.
Marco, Lou
"In Praise of PL/I"
Enterprise Systems Journal, Dec 1995; 32-37.
MacLaren, M. Donald
"Exception handling in PL/I"
Proceedings of an ACM conference on Language design for reliable software, Mar, 1977; 101-104.
McCracken, Daniel D.
"The New Programming Language"
Datamation, Jul 1964; 31-36.
Myers, G.J.
"Composite design facilities of six programming languages"
IBM Systems Journal 15(1976): 212-224.
Pantages, Angela
"Language Objectives of the Late 60's"
Datamation, Nov 1965; 141-142.
Pohl, Ira
"Phas-structure productions in PL/I: Phas-structure productions in PL/I0"
CACM 10(1967); 757.
Radin, George
"The Early History and Characteristics of PL/I"
ACM SIGPLAN History of Programming Languages Conference, Jun 1978; 227-241.
Rubey, Raymond J.
"A comparative evaluation of PL/I"
Datamation, Dec 1968; 22-25.
Schroeder, E.B.
"Odes to a new language"
Datamation, Dec 1968; 39.
[verse]
Shaw, Christopher J.
"PL/I for C&C"
Datamation, Dec 1968; 26-31.
Sibley, R.A.
"A New Programming Language: PL/I"
Proceedings of the 20th National Conf., Assoc. for Computing Machinery (1965):543-563.
Siler, Kenneth F.
"A PL/I model of an emergency medical system"
Proceedings of the 6th Conference on Winter Simulation, Assoc. for Computing Machinery (1973):882.
Sitton, Gary A., Kendrick, Thomas A., and Carrick, jr., A. Gil.
"The PL/EXUS Language and Virtual Machine"
Proceedings of the ACM-IEEE symposium on high-level-language computer architecture, Nov 1973:124-130.
Sugimoto, Masakatsu
"PL/I Reducer and Direct Parser"
Proceedings of the 24th National Conf., Assoc. for Computing Machinery (1969):519-538.
Symonds, A.J.
"Interactive Graphics in Data Processing: Auxiliary-storage associative data structure for PL/I"
IBM Systems Journal 7(1968):229-245.
Tenny, T.
"Program Readability: Procedures vs. Comments"
IEEE Transactions on Software Engineering; 14(1988): 1271-1279.
Vowels, Robin A.
"PL/I for OS/2"
ACM SIGPLAN Notices, March 1996; 22-27.
Voysey, Hedley
"PL/I in the UK"
Datamation, Sep 1967; 73-74.
Wade, Bradford W., and Schneider, Victor B.
"A general-purpose high-level language machine for minicomputers"
Proceedings of the meeting on SIGPLAN/SIGMICRO interface, May 1973:169-171.
Wagner, R.A., and Morgan, H.L.
"PL/C: The design of a high performance compiler for PL/I"
AFIPS Conference Proceedings: 1971 Spring Joint Computer Conference, 1971; 503-510.
Wegner, P.
"The Vienna Definition Language"
Computing Surveys 4(1972): 5-63.
Weisert, Conrad
"Has the King Returned?"
ACM SIGPLAN Notices, April, 1993; 9-10.
Wolman, Barry L.
"Debugging PL/I Programs in the Multics Environment"
AFIPS Conference Proceedings: 1972 Fall Joint Computer Conference, 1972; 507-514.
Wortman, D. B.
"Student PL - A PL/I Dialect Designed for Teaching"
Proceedings of Canadian Computer Conference, Montreal, Jun 1972
Wortman, David B., Khaiat, Phillip J., and Lasker, David M.
"Six PL/I Compilers"
Software-Practice and Experience 6.3 (1976): 411-422
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Created: May 16, 1996; Last modified: July 20, 2021